Contenido de la asignatura.
- Introducción
- Internet
- Aplicaciones básicas
- El súper servidor Inetd
- Telnet
- FTP
- Sobre la realización de las prácticas
- Práctica de herramientas básicas
- Práctica del escritorio remoto
- Comandos r
- SSH
- Preparación del entorno con un par de llaves
- Acceso a puertos bloqueados
- Uso remoto de aplicaciones locales
- Uso del agente, escenario 1
- Uso del agente, escenario 2
- Uso del agente, escenario 3
- Práctica de SSH
- Rsync
- Práctica de Rsync
- Network File System (NFS)
- Cuestiones del tema
- DNS, sistema de nombres de dominios
- Dominios
- Delegación de autoridad
- Resolución directa y resolución inversa
- Relación entre servidores
- BIND
- La resolución de nombres en un ordenador
- Práctica del servidor de nombres
- Cuestiones del tema
- El correo electrónico
- Las direcciones de correo
- Funcionamiento
- SMTP básico
- Relays, spam
- POP3, IMAP, Webmail
- Agentes de transporte
- Práctica de postfix
- Formato del mensaje
- Práctica del correo
- Cuestiones del tema
- El World Wide Web
- Fundamentos. URLs
- El protocolo HTTP
- Servidor Web Apache
- Práctica de Apache
- El lenguaje HTML
- Introducción
- Estructura básica de un documento HTML
- Otras etiquetas
- Hipervínculos o enlaces
- Tablas
- Formularios
- El lenguaje PHP
- Práctica del World Wide Web
- Cuestiones del tema
- Cuestiones generales
- Apéndices
- Ejemplos de configuración clásica de redes
- Red segmentada
- Red segmentada a través de una red privada
- ADSL sin NAT
- Uso de proxyarp.
- Configuración de una interfaz wifi
- Ejemplos de configuración moderna de redes
- NAT
- Varios encaminadores por defecto
- Selección de ruta
- ADSL con NAT en el router
- Varios proveedores
- Un ejemplo real.
- Otro ejemplo.
- Un túnel IP-gre-IP
- Un ejercicio práctico
- Ejemplos MIME
- Más en NiSu ...
Introducción
Estos apuntes son una aproximación al contenido de la asignatura Gestión de Servicios de Internet.La asignatura pretende cubrir las capas superiores de la arquitectura de redes, centrándonos en la única red universal, Internet. Así, estudiaremos el funcionamiento y administración de algunos servicios fundamentales de Internet, el servidor de nombres, el correo y el web, sin olvidar aplicaciones básicas de uso profesional y una introducción a las redes.
Los temas se acompañan de prácticas y al final de cada tema hay una colección de cuestiones resueltas. El calendario que se propone es el de prácticas para los grupos presenciales y de teoría y prácticas para el grupo semipresencial.
Internet
La importancia de Internet en nuestra vida diaria justifica la existencia de una asignatura dedicada a la gestión de los servicios de Intenet. Cuando escribimos Internet en mayúscula, nos referimos a una red concreta y muy popular. Se trata de una red de tipo internet (en minúscula), una red basada en el protocolo IP. Por encima del protocolo IP se implementan TCP (añade fiabilidad a las comunicaciones, controlando corrección extremo a extremo, con independencia de las trayectorias de cada datagrama individual y la suerte que haya podido sufrir) y UDP (acceso directo a IP). Estos protocolos permiten que varios programas de un mismo ordenador se pueden comunicar concurrentemente con programas de otros. TCP es tan empleado que a las redes IP se las suele llamar redes TCP/IP.En 1969 se creó la primera red internet, conocida como ARPANET. Esta red fue la conexión de ordenadores entre tres universidades en Californa y una en Utah, Estados Unidos y disponía de un conjunto de servicios muy pequeño.
Internet ha evolucionado rápidamente desde 1995, desarrollándose numerosos protocolos a nivel de aplicación e innumerables servicios. Uno de los servicios que más éxito ha tenido en Internet ha sido sido el World Wide Web (WWW, o "la Web"), hasta tal punto que que es habitual la confusión entre Internet y este término, quizá porque sobre la Web se construyen innumerables aplicaciones, de hecho la mayoría de las empleadas por el usuario final.
Repaso de TCP/IP
Para administrar un sistema que preste servicios de Internet, aparte de los conocimientos básicos en administración de sistemas operativos, es necesario conocer a fondo la configuración de la red. Por ello ahora repasamos los conceptos básicos de Internet y en los apéndices se incluyen numerosos y complejos ejemplos de configuración de redes.Arquitectura de Internet
Una red internet se apoya en el protocolo IP. Las ideas fundamentales de una red basada en IP son:- Cada ordenador conectado a la red tiene un número de protocolo IP (abreviadamente diremos una dirección IP o más brevemente, una IP) que debe ser único.
- Los datagramas IP se transmiten encapsulados en un protocolo de nivel inferior (ethernet, wifi, etc.).
- Diremos que una IP es directamente alcanzable si para llegar a ella basta con emplear el protocolo de nivel inferior.
- Si una IP no es directamente alcanzable, al menos un equipo directamente alcanzable (encaminador o router) se encargará de encaminar los datagramas hacia dicha IP.
- El encaminador estará, por otro interfaz, conectado a otra red con la misma situación, con lo que por inducción construimos la red internet. El resultado es una red fácilmente expansible.
- Qué conozca qué IPs son directamente alcanzables.
- Qué IP actuará de router para conectarlo con el resto de la red.
- Que las demás IPs de la red conozcan una ruta hacia él.
En IPv4, una IP tiene 32 bits. Para una escritura más cómoda, se escribe como x.x.x.x, donde x es un número de un byte. Así por ejemplo, 172.18.0.6 es la IP de este servidor y es la IP que este servidor ve de tu ordenador. Dada una IP, las IPs directamente alcanzables son IPs con un número similar, formando un conjunto determinado por la denominada máscara de red. Así 192.168.27.5/21 indica un conjunto de IPs cuyos 21 primeros bytes son los mismos. La primera sería 192.168.24.0 que no es una IP utilizable para un ordenador, sino que representa la dirección de la red, que se escribe como 192.168.24.0/21. La última es 192.168.31.255, que normalmente tampoco es utilizable y se denomina dirección de broadcast. Si no se especifica la máscara de red, según la IP se deduce una máscara implícita (redes de clase A, B, C, etc,).
Dentro del espectro de direcciones de Internet, existen ciertas IPs reservadas (a veces se les llama privadas) que se caracterizan por no ser nunca encaminadas dentro de Internet. Su próposito es que podamos construir otras redes IP (otras internets), separadas de Internet, pero con IPs que no coincidan con IPs que puedan estar usándose en Internet (las llamadas públicas para distinguirlas de las privadas). Estas IPs privadas son las 10.x.x.x, las 172.16.x.x y las 192.168.x.x. Es decir, que emplearemos estas IPs por ejemplo para montar una red en casa, separada de Internet, pero compatible. Obsérvese que las mismas IPs pueden usarse en muchos sitios, puesto que jamás se encaminan en Internet, no forman parte de ella.
El nivel inferior (enlace) no entiende las direcciones de IP, necesita una dirección física
(dirección MAC en el caso de Ethernet). Cuando un ordenador con una IP necesita acceder a otra IP de su red, usa el
nivel inferior, y a través del protocolo ARP, pregunta qué ordandor tiene la IP que busca y éste le responde cuál es su dirección en el protocolo
inferor, de modo que enviará los datagramas a esa dirección.
El comando: arp -na nos muestra las direcciones físicas de equipos de nuestra red que recientemente han conectado con el nuestro.
Se trata de una tabla donde se cachean durante un breve periodo de tiempo las direcciones obtenidas.
El protocolo RARP es el inverso de ARP, Este protocolo es necesario cuando arrancan ordenadores remotos (sin disco) que solo saben su dirección física almacenada en ROM del hardware de red, y necesitan su dirección IP para conectarse. Más avanzados son BOOTP y DHCP, que permiten suministrar como respuesta no sólo la IP que debe asignarse al equipo sino la dirección del encaminador y la dirección de los servidores de nombres que puede usar.
Un ejemplo de configuración básica de una red puede verse aquí.Veamos la configuración básica de una red. La figura muestra la clase C 194.1.2.0/24. La primera IP es la del router, del que no nos preocupamos de la parte conectada a Internet, pues operando por inducción entendemos correctamente configurada. Debemos recordar ahora que lo más importante es que los paquetes destinados a esta clase C se encaminen en el resto de Internet hacia este router, cosa que damos por supuesta. Ahora nos queda configurar la red correctamente. Por simetría, basta con escoger cualquier equipo, en la figura lo hemos marcado con una A. Inicialmente ejecutamos el comando:
ip link set dev eth0 upque provoca la carga los módulos del kernel necesarios (suponiendo module autoload) y levanta la interfaz eth0. Este comando no lo repetiremos en los demás ejemplos.
| A | |||||
| 194.1.2.2 |
|||||
| 194.1.2.3 |
|||||
| 194.1.2.1 |
|||||
| 194.1.2.5 |
|||||
| eth0 |
ip a a 194.1.2.2/24 dev eth0 |
Esta es la configuración básica de un equipo con una IP de Internet. Dispone de una IP sobre el interfaz eth0 y al añadir la IP, el comando ip amablemente nos enruta la red local, con lo que el comando marcado con # no necesita ejecutarse. |
ip r a default via 194.1.2.1 |
Al final añadimos una ruta por defecto a través de un router que pertenece a la red que acabamos de enrutar. |
Encaminamiento ^
En el IP clásico, se usa una tabla que asocia redes con las pasarelas por las que estas pueden ser alcanzadas, esta tabla estará presente tanto en máquinas que actúen como encaminador como en otras que sean simples hosts. Cada entrada de la tabla consiste en:- Un destino, es decir la IP que se puede alcanzar, que puede ser una red. Se usa la partícula default para referirse a el resto de las direcciones posibles.
- Una distancia, que indica el número de saltos que se darán para llegar al destino, es habitualmente cero si la configuración es manual,
- Una máscara, que determina el tamaño de la red destino, puede introducirse manual o automáticamente (según la clase A, B,C).
- Una pasarela (encaminador, router).
- Una interfaz.
- Las entradas se examinan por orden, determinado por el tamaño de la red destino, las más pequeñas primeroi, teniendo en cuenta que un equipo es una red de tamaño 1 y la ruta por defecto es la red mayor.
- Cuando se encuentra una red que contiene la IP destino se toma esta entrada y el paquete se transmite:
- por el interfaz que indica
- directamente o a través de la pasarela si está indicada.
Las necesidades del enrutamiento actual han llevado a que el TCP/IP clásico sufra modificaciones.
Por ello debemos conocer como selecciona el kernel la IP de origen y si procede, forzar la selección de una determinada IP cuando nos interese. Las reglas son:
- La aplicación origen selecciona ya una IP mediante la llamada al sistema bind. El kernel lo respeta y selecciona además la ruta correspondiente.
- Las tablas de rutas contienen una ruta para el destino dada con el parámetro src del comando ip route
- Determinada la ruta, el kernel selecciona la primera IP válida con el ámbito (scope) adecuado que esté en la misma subred que el encaminador seleccionado.
- Si no, se selecciona la primera IP con el ámbito adecuado.
Una sola tabla de encaminamiento no satisface las necesidades del enrutamiento actual. Actualmente pueden definirse varias tablas de enrutamiento y selectores que determinan cuál es la que va a emplearse. Así un selector predefinido establece cual es la tabla principal, compatibilizando con el enrutamiento clásico, pero podemos definir nuevas tablas y selectores que determinen qué tabla usar. Estos selectores trabajan con diversos parámetro, destacando la IP origen y la IP destino.
Otro elemento importante del encaminamiento actual es el NAT (traducción de red), realizado por los routers.
En el caso del source NAT (SNAT), cuando un paquete IP llega al router, éste sustituye la IP de origen
del paquete por la suya, y reenvía el paquete, de modo que el destinatario lo recibe como si viniera del router.
Al devolver la respuesta, ésta llega al router, quien la reenvía al origen real. Obviamente el router tiene
que recordar todas y cada una de las transformaciones realizadas para reenviar cada una a su origen real. Éste es el
mecanismo que emplean los routers domésticos para que diversos ordenadores de una red local puedan acceder a
Internet con una sola IP válida de Internet, la IP del router.
Frente a SNAT, en el DNAT (destination NAT) la IP cambiada es la IP destino. Este es el mecanismo que
emplean los routers domésticos para redirigir las peticiones que llegan a la IP pública de Internet, a
un determinado equipo dentro de una red local de IPs privadas, necesario para que funciones ciertos programas, como
eMule.
Túneles ^
El tunneling es una técnica de empaquetamiento. Consiste en añadir nuevas capas IP sobre un soporte IP ya existente. Supongamos dos ordenadores conectados a Internet, cada uno con una IP válida, pero pertenecientes a dos redes completamente distintas. Cuando uno quiere conectar con el otro sólo tiene que especificar el destino, y los routers intermedios se encargarán de encaminar los paquetes. Podemos imaginar que ambos están unidos por un cable virtual sobre el que podemos establecer sesiones telnet o servicios HTTP. Nada nos impide, sobre este cable virtual, establecer otra estructura IP. En este momento Internet actuará como un túnel para los nuevos paquetes IP que viajarán empaquetados en la estructura IP válida en internet. Entre ambas capas IP pueden existir otros protocolos. Si no los hay será un túnel IP-IP, pero puede haber túneles IP-GRE-IP, IP-PPP-IP, etc. En los apéndices hay un ejemplo de túnel gre.TCP ^
El protocolo IP permite transferir información de un ordenador a otro, pero no permite distinguir la naturaleza de la misma. Por encima de IP, el protocolo TCP añade un atributo, el puerto, que se emplea para indicar el tipo de información que se está intercambiando. Además, el protocolo garantiza que los datos serán entregados en su destino sin errores y en el mismo orden en que que fuerón enviados.La cuádrupla (IP origen, puerto origen, IP destino, puerto destino) determina una comunicación entre dos equipos y desde los programas se realiza a través de los sockets. Los sockets son puntos de acceso desde los programas al TCP/IP, manejándose como descriptores de fichero. Los socket no son exclusivos de TCP, aparecen en otros protocolos, como UPD.
Modelo Cliente/Servidor ^
Este modelo consiste en asignar roles a los ordenadores de la red. El ordenador que hace el rol de servidor se encarga de tener una aplicación escuchando peticiones de un determinado puerto. Cuando al servidor le llega una petición al puerto responde al cliente y asi se crea un servicio. El ordenador que hace el rol de cliente se encarga de realizar peticiones al servidor por dicho puerto. Obviamente, un ordenador puede dar varios servicios y ser a su vez cliente de muchos servicios.Hay una estandarización por la que se asocian puertos y servicios, por ejemplo para conexiones FTP se utiliza el puerto 21. Se pueden definir hasta 216 puertos en un ordenador, la única resticción es que el sistema operativo no permite al usuario utilize puertos menores al 1024, pues son lo que se usan para definir los principales servicios del sistema. Si se quieren definir servicios en los puertos menores al 1024 los tiene que definir el administrador.
Estos son los principales servicios, una lista completa se halla en /etc/services| Puerto | Servicio | Programas servidores del servicio |
|---|---|---|
| 21 | ftp | ftpd,proftpd,vsftpd |
| 22 | ssh | sshd |
| 23 | telnet | telned |
| 25 | smtp | sendmail,postfix,qmail |
| 53 | DNS | named |
| 80 | WEB | apache |
| 110 | pop3 | in_pop3d, courier_pop, cyrus_pop |
| 143 | imap | in_imapd, courier_imap, cyrus_imap |
| 443 | https | mismos que http |
| 992 | pop3s | mismos que pop3 con una capa TLS |
| 993 | imaps | mismos que imap con una capa TLS |
Cuestiones del tema ^
Nota: Lo que realmente sucede es otra cosa, pruébalo y encuentra una explicación.
- Una página web me muestra (entre otras cosas) una imagen, cuya URL quiero averiguar.
Cuando pulso el botón derecho para desplegar el menú contextual me dice que el botón derecho está deshabilitado. ¿Qué puedo hacer?
Resp.Deshabilitar el javascript.
- Una página web me muestra (entre otras cosas) una imagen, cuya URL quiero averiguar.
Pulso el botón derecho para desplegar el menú contextual, eligo "Ver imagen" y me sale una imagen transparente de 1 pixel.
¿A qué se puede deber? ¿Cómo podré sacar la imagen que quiero ver?
Resp.La imágen que veo es el background de una imágen de 1 pixel expandida al tamaño del fondo. Para ver la original, puedo elegir "Ver información de la página" y en la lista de "Media" veré la imagen.
Lo importante es tener claro que es algo que está sucediendo a nivel del cliente y por más que lo intenten, yo siempre podré manipular el cliente. Probablemente existen otras formas de intentar evitarlo, como divs con fondo transparente sobre el texto, pero, inisito, siempre bajo el control del cliente.
En el caso 2, el cliente inicia primero vncviewer -listen y el servidor puede ejecutar x11vnc -conect hostcliente 5500 donde 5500 es el puerto que nos indique vncviewer -listen. También puede usarse en el cliente vncconnect.
La utilidad práctica le modo Listen es hacer mantenimiento remoto de ordenadores que están detrás de un cortafuegos, el técnico tiene un ordenador que sí puede recibir conexiones remotas, pero el cliente no, así que el técnico le dice al cliente que lance el modo Listen contra su oordenador.
Aplicaciones básicas ^
El súper servidor Inetd
Los programas que proporcionan servicios de aplicación a través de la red se llaman demonios. Un demonio es un programa que abre un puerto, comúnmente un puerto de algún servicio bien conocido, y espera conexiones entrantes en él. Si ocurre una, el demonio crea un proceso hijo que acepta la conexión, mientras que el proceso padre continúa escuchando más peticiones. Este mecanismo funciona bien, pero tiene unas pocas desventajas; al menos una instancia de cada posible servicio que se quiera proporcionar, debe estar activa en memoria a todas horas. Además, la rutina software que hace la escucha y la gestión del puerto tiene que ser replicada en cada uno de los demonios de red.Para superar estas ineficiencias, muchas instalaciones Unix ejecutan un demonio de red especial, el cual debe ser considerado como un súper servidor. Este demonio crea sockets en nombre de cada uno de los servicios y escucha en todos ellos simultáneamente. Cuando una conexión entrante es recibida en cualquiera de esos sockets, el súper servidor acepta la conexión y replica el servicio especificado para ese puerto, pasando el socket a gestionarse a través del proceso hijo. El servidor entonces, vuelve a la escucha. El súper servidor más común se llama inetd, el Demonio de Internet. Se inicia en tiempo de arranque del sistema y toma la lista de servicios que ha de gestionar de un fichero de iniciación llamado /etc/inetd.conf, donde se especifica el programa que debe lanzar para tratar el servicio solicitado.
Ventajas de usar inetd:
- La aplicación que trata el servicio no sabe nada de TCP/IP.
- La aplicación no consume recursos si nadie gasta el servicio, sólo esta activo inetd.
- Útil para aplicaciones que se usen de forma esporádica o para aplicaciones de sesión; pero es muy poco eficiente para servicios que reciben muchas conexiones, como WWW.
- Ineficiente cuando la carga de los archivos de configuración de la aplicación es muy costosa.
Telnet
Telnet es un protocolo informático que emula un terminal remoto para conectarse a una máquina multiusuario. El servidor escucha el puerto 23 y el cliente conecta con él cuando desea mantener una sesión remota. La conexión TCP permanece abierta durante toda la sesión, es decir que la sesión de trabajo remoto dura lo mismo que la sesión TCP.El cliente telnet intenta realizar la emulación de un terminal físico (actualmente en desuso) y por ello, primero negocia el modelo de terminal a emular, frecuentemente un VT100 o superior. A partir de ahí, el cliente tiene la sensación de que esta en la máquina remota ya que todo lo que teclea lo manda a la máquina remota y todo lo que produce esta lo recibe el cliente.
Este servicio solo sirve para acceder en modo terminal, es decir, sin gráficos, pero fue una herramienta muy útil
para reparar problemas a distancia. También se utilizó para consultar datos a distancia, como datos personales accesibles
a través de internet, información bibliogáfica,etc.
Los requisitos para acceder a este servicio son muy sencillos: conocer el nombre y la dirección de servidor remoto y
estar autorizados mediante un identificador de usuario y contraseña para poder utilizarlo, y es que, claro está,
el servidor antes de permitir acceso invoca al programa login para autenticar al usuario remoto, igual
que en un terminal físico de un equipo multiusuario.
El principal problema de este servicio es de seguridad ya que todos los datos que se envian y se reciben se envian por la red sin cifrar. Estos datos incluyen el usuario y la contraseña, por tanto, si en el momento de la autenticación, alguien está espiando la red podría obtener estos datos y conectarse a la máquina usurpando la identidad del propietario de la contraseña. Por estas y otras razones éste servicio ha sido masivamente reemplazado por ssh. No obstante, por su naturaleza sencilla de teminal remoto, seguimos empleándolo para realizar conexiones remotas buscando depurar protocolos de más alto nivel como SMTP, POP, HTTP, etc., como veremos en la práctica correspondiente.
FTP
El servicio de transferencia de ficheros permite transferir ficheros entre ordenadores utilizando el protocolo FTP (File Transfer Protocol). Aunque el término FTP hace referencia al protocolo empleado, se suele utilizar indistintamente para nombrar tanto el protocolo como el servicio asociado. Si disponemos de un ordenador que presta dicho servicio y, por otra parte, de un cliente FTP, podremos transferir ficheros desde el cliente hasta el servidor o viceversa. En general es un servicio que requiere autenticación, aunque existen servidores abiertos (se accede con un usuario genérico denominado ftp o anonymous.El protocolo FTP utiliza el puerto 21 para la conexión entre cliente y servidor, pero para la transferencia de datos se solía emplear el puerto 22, aunque está en desuso. También cabe destacar que el servicio FTP no ofrece integridad alguna de los datos transmitidos y que los datos no se transportan cifrados, como hace por ejemplo scp.
Respecto a la transmisión de datos, existen dos modos. En el modo activo, el originalmente habitual en el FTP, el cliente pide una operación al servidor, pero es éste quien la realiza, es decir, en el momento de realizar una petición de un recurso, será el servidor quién conecte con el cliente. El problema de este modo es que hoy en día es habitual que el cliente esté detrás de un NAT, lo que requiere usar el modo pasivo. En este modo, es el cliente quien inicia todas las conexiones, y se realizan por pueros que se negocian dinámicamente.
El protocolo FTP se compone de una serie de comandos que el cliente envía al servidor solicitando las distintas operaciones que pueden relizarse.
A nivel de uso, a la hora de transferir ficheros hay dos tipos de transferencias posibles, modo texto y binario. Es fundamental establecer el tipo de transferencia adecuado para cada fichero, pues en caso contrario el resultado de la transferencia sería un fichero no válido. La transferencia en modo binario es la requerida en la mayoría de los casos. Al utilizar este modo de transferencia, el fichero que obtenemos es exactamente igual al fichero original.
El problema se plantea en el caso de los ficheros de texto, pues éstos presentan algunas diferencias en función del sistema en el que estemos trabajando. Por ejemplo, en Linux se utiliza un único carácter para representar un salto de línea en un fichero de texto, mientras que en DOS/Windows son necesarios dos caracteres. Si transferimos en modo binario un fichero de texto desde Windows hasta una máquina Linux, el fichero obtenido será exactamente igual al original, pero los editores de texto podrían no reconocerlo de forma adecuada, ya que la representación de los finales de línea no sería la esperada (sobraría un carácter por línea). Del mismo modo, si enviásemos en modo binario un fichero de texto desde una máquina Linux hasta un sistema Windows, el final de cada línea sería incorrecto (faltaría un carácter por cada línea). Cuando establecemos la transferencia en modo texto, los ficheros son modificados en la forma necesaria según el tipo de los sistemas origen y destino. Es decir, los ficheros obtenidos no son "exactamente" iguales a los originales, sino que han sido modificados para adaptarlos al nuevo sistema. Por otra parte, si transfiriésemos en modo texto un fichero binario (por ejemplo, una imagen en formato jpg), se realizarían modificaciones sobre el mismo durante el proceso de transferencia, por lo que el resultado sería un fichero no válido.
El cliente tradicional FTP es un cliente en línea de comandos. Éste cliente muestra un inductor y el usuario introduce comandos. Estos comandos son muy similares a los del propio protocolo FTP, pero no deben confundirse. El comando de cliente denominado site permite enviar comandos del protocolo FTP al servidor directamente. Los clientes visuales, como Filezilla, son hoy en día más habituales, pues el usuario no necesita conocer ningún comando. Ambos tipos de cliente los ensayaremos en la práctica correspondiente. Poner los comando sdel protocolo, no los del cliente.
Sobre la realización de las prácticas ^
Para la realización de las prácticas de esta asignatura necesitas tener una cuenta en al.nisu.org. Probablemente tu profesor ya la ha creado, para acceder puedes establecer tú mismo la contraseña, simplemente acude a la página principal de dicho servidor.Aunque los enunciados de las prácticas están pensados en su mayoría para que puedas realizarlas en casa, lo normal es realizarlas en los laboratorios dentro del horario. Dichos laboratorios no disponen de la integración en el sistema de autenticación de la UJI. Es decir, cuando arrancas el Linux (o Windows) instalado dispones de un ususario genérico usuario. El inconveniente es que no puedes guardar ninguna configuración personalizada de tus aplicaciones. Además, todo lo que dejas en el disco duro queda a la disposición de otros estudiantes y se borra periódicamente.
Para resolver el problema, cuando Linux arranca, una vez ha iniciado el kernel, mantén pulsada la tecla de borrar (la que está encima de "Intro"). Te solicitará usuario y contraseña (la de Nisu, no la de la UJI) y te creará un usuario local con tu alxxxxxx. A partir de ahí podrás trabajar con tu usuario, y tus archivos se guardarán, no en local, sino en red, pues tu directrorio local (del PC del laboratorio) se ha montado sobre el directrorio home_aulas que tienes en tu cuenta en Nisu, que obviamente no debes borrar. Como resultado, nada de lo que guardes en tus directorios queda en el PC, sino que se conserva en Nisu para la próxima sesión.
A esta situación le denominaremos usuario autenticado en el laboratorio.
Comandos r ^
Estos comandos han sido también superados por SSH, que incorpora sus funciones incluso a nivel de configuración. No obstante, al ser mucho más rapido su setup, se emplean en redes locales con alto grado de confianza, como por ejemplo un clúster de computación con procesos distribuidos. Los comandos r son:- rexec se utiliza para ejecutar un programa en otra máquina. Un ejemplo de su uso sería rexec B programa, siendo B la máquina donde va a ejecutarse el programa. No suele emplearse directamente por el usuario sino por aplicaciones, para el usuario es más cómodo el rsh.
- rlogin [-l usuario] servidor permite abrir una sesión de trabajo en el servidor, similar a un telnet. Cuando el servidor recibe la petición:
- Comprueba que el puerto origen es menor que 1024. Así sabe que es el programa originalmente instalado por el administrador de la máquina cliente.
- El programa cliente le envía el usuario que ejecuta la petición, que puede ser distinto del usuario solicitado con la opción -l.
- Consulta el fichero /etc/hosts.equiv. Si el ordenador cliente está en la lista lo admite si el nombre de usuario es el mismo.
- Si no, consulta el archivo ~/.rhosts (del usuario solicitado). Este archivo se compone de líneas de la forma máquina [usuario cliente]. Si la pareja (máquina cliente, usuario cliente) figura en él, lo admite.
- Si no, pide la contraseña del usuario solicitado.
- rsh [-l usuario] servidor comando argumentos, ejecuta el comando en la máquina remota. El proceso de autenticación es como el de rlogin, pero no pide la contraseña si el proceso automático falla, simplemente rechaza la operación. El comando rsh se comporta como rlogin cuando no se especifica ningún comando.
- rcp ficheros [usuario@]servidor:[path], copia los ficheros en la máquina servidor accediendo con el correpondiente usuario. El procedimiento de autenticación es el de rlogin. Si el path es un fichero sólo puede copiarse un fichero, si es un directorio pueden copiarse varios. Obsérvese que rcp unfichero unservidor:otrofichero es lo mismo que rsh <unfichero unservidor "cat >otrofichero". La opcion -p realiza la copia preservando la hora y los permisos del fichero.
SSH ^
Podemos pensar en SSH como un protocolo pensado para dotar de seguridad a telnet o los comandos r. De hecho los comandos ssh y scp heredan la sintaxis y el comportamiento global de rsh y rcp respectivamente. Vemos muy brevemente las características nuevas de ssh. Para entenderlas bien se requiere conocer un minimo de criptografía de llave pública.- En primer lugar la transmisión de datos se realiza cifrada.
Para ello el cliente debe conocer la llave pública del servidor o aceptarla la primera vez, con las consideraciones de seguridad implicadas.
A partir de ahí se establece una llave de sesión y se cifra la transmisión. - La autenticación puede ser por contraseña o mediante un par de llaves.
- En el caso de usar contraseña, simple pero incómodo, la contraseña es solicitada cada vez, a diferencia de rsh. Obviamente es la contraseña que el usuario dispone en el servidor, como en rlogin.
- En el caso del par de llaves, el cliente debe disponer de un par de llaves (que puede haber generado previamente con ssh-keygen),
comúnmente de tipo RSA. La llave privada estará en el cliente, normalmente almacenada en ~/.ssh/id_rsa, la llave pública en ~/.ssh/id_rsa.pub.
Si el contenido de este archivo ha sido añadido al archivo ~/.ssh/authorized_keys del servidor, funcionará la autenticación mediante par de llaves. Si la llave privada está protegida por contraseña, ésta se solicitará al cliente en el momento de cargarla. No debe confundirse con la contraseña del servidor, que no interviene en este modo de autenticación.
- Permite redirección de puertos, algo similar a un túnel. Se realiza especificando: -L puerto_local:servidor:puerto_remoto y -R puerto_remoto:maquina_local:puerto_local. En los ejemplos veremos cómo usarlo.
- Permite redireccionar las Xwindow, usando la opción -X.
Para ello en el remoto se crea un display virtual que es redireccionado al local, mejorándose la transmisión si se emplea además la compresión de datos (con -C).
Para poder comprender lo explicado, es necesario ver algunos ejemplos y realizar la práctica.
Preparación del entorno con un par de llaves
Queremos acceder a un servidor al que tenemos acceso SSH usando autenticación mediante llave RSA. Podemos hacerlo usando ssh-copy-id, pero lo haremos a mano:ssh-keygen -t rsa | Esto sólo lo hacemos si no tenemos ya una llave. Si ya disponemos de ella, nos saltaremos este paso. Podemos dejar la contraseña vacía. |
cat ~/.ssh/id_rsa.pub | Simplemente visualizamos la llave pública que se ha generado. |
ssh servidor "cat >>~/.ssh/authorized_keys" <~/.ssh/id_rsa.pub | Añade al fichero de llaves autorizadas del servidor la llave que deseamos. Aquí solicitará la contraseña del servidor. |
ssh servidor ls | Comprobamos que funciona: lista los ficheros sin pedir ninguna contraseña. |
Acceso a puertos bloqueados
Supongamos que desde casa quiero enviar correo con thunderbird usando como servidor saliente un ordenador que está detras de un cortafuegos y no tengo acceso a su puerto 25. No obstante tengo acceso SSH a ese ordenador.Configuro entonces thunderbird para que use como servidor saliente localhost, puerto 2500, y ejecuto:
ssh -fN -L 2500:localhost:25 miuser@elservidorEsto provoca una conexión SSH con el servidor, pero que no hace nada (-N), simplemente se queda en marcha para redirigir puertos, y además no me bloquea el terminal (-f provoca un fork después de la autenticación y la aplicación se queda en segundo plano). La redirección de puertos (-L) hace que cualquier conexión a local por el puerto 2500 se envíe por SSH y se realice en el servidor una conexión a él mismo (localhost) por el puerto 25.
Si no tuviera acceso SSH al servidor de correo, pero sí a otra máquina desde donde sí puedo acceder al puerto 25 del servidor, haría:
ssh -fN -L 2500:elservidor:25 miuser@otramaquinade modo que las peticiones al 2500 de mi máquina se envían por SSHa la otra máquina remota, y ésta las reenvía al servidor, puerto 25. Es decir, que la conexión SSH entre mi ordenador y la otra máquina es como un tunel que transfiere la conexión a mi ordenador en el puerto 2500 al servidor en el puerto 25.
Uso remoto de aplicaciones locales
El clauer se opera a través de un demonio que escucha peticiones por el puerto 969, pero sólo escucha la IP 127.0.0.1, es decir que sólo pueden operar aplicaciones locales. Meto el clauer en en mi ordenador pero quiero que pueda usarlo un firefox arranco en una máquina remota (donde no hay demonio del clauer). Para ello hago:ssh -fN -R 969:localhost:969 root@maquina | Necesito ser administrador en la máquina remota para poder escuchar ese puerto, lanzo el proceso con -fN para que sólo redirija puertos y no moleste. |
ssh -X user@maquina firefox | Ejecuto firefox con redirección X. |
Uso del agente, escenario 1
Sean dos servidores, tengo una llave privada en mi ordenador que me da acceso a ambos, pero para acceder a servidor2 tengo que pasar por servidor1, que no tiene copia de la llave.eval $(ssh-agent) | Arranco el agente, sólo si no lo está. |
ssh-add | Añado mi llave privada. |
ssh -A servidor1 | Entro en servidor1, manteniendo la conexión con el agente. |
ssh servidor2 | Desde servidor1 accedo a servidor2. Como tengo la conexión con el agente de mi ordenador, uso la llave, que no está copiada en servidor1. |
Uso del agente, escenario 2
Sean dos servidores, la llave para acceder a servidor1 la tengo yo, pero la de acceder a servidor2 está en servidor1 y quiero acceder a servidor2 desde mi casa.ssh -A servidor1 | Supongo el agente arrancado, accedo a servidor1 propagando la conexión con el agente que está en mi ordenador. |
ssh-add | En servidor1 añado la llave que hay allí guardada, al agente de mi casa. |
exit | Vuelvo a mi ordenador. Esos tres comandos pueden hacerse con uno solo. |
ssh servidor2 | Ya puedo entrar en servidor2 porque en el agente de mi casa tengo la llave copiada. |
Uso del agente, escenario 3
Sean diez servidores. Accedo a los servidores 1...9 a través del 0, pero ni mi ordenador ni el servidor 0 tienen la llave que me da acceso a los demás, está en servidor9. Quiero copiar un mismo fichero de mi ordenador a los 9 servidores 1...9.ssh -A servidor0 ssh -A servidor9 ssh-add | Con el agente inicado en mi ordenador, accedo al servidor 0 manteniendo la conexión con mi agente, pero sólo para ejecutar el comando que accede al servidor 9, donde cargo la llave. Sigo en mi ordenador, no he entrado en ningún servidor. |
for s in 1 2 3 4 5 6 7 8 9; do | Para cada servidor 1...9, copio el fichero pasando por el servidor 0. Obsérvese la necesidad de comillas " fuera y comillas ' dentro. Ver las cuestiones del tema. |
Rsync ^
Rsync es una excelente aplicación para mantener copias idénticas de directorios en dos ordenadores, incluso para copiar archivos sueltos entre dos máquinas. Es incluso recomendable para copiar archivos grandes en un mismo ordenador por poder establecer una velocidad de copia controlada que no aumente la carga del sistema. Uno de los puntos de interés de Rsync es su capacidad de transmitir sólo aquellos datos que han sido modificados entre el origen y el destino.Se puede usar en dos modos básicos: el remoto es un servidor o el remoto es un esclavo.
El remoto es esclavo
Se requiere un modo externo de conectar con la máquina remota (por defecto ssh). No es necesario que haya un servidor Rsync funcionando, sólo que esté disponible el programa rsync en ambas máquinas. Se identifica este modo por la especificación del remoto según servidor:objeto. Ejemplo:rsync -e ssh --bwlimit=10 -acvP *.avi mon@servidor:sueltos/ | Conectará con el servidor remoto vía ssh y arrancará una instancia de rsync en modo esclavo (--server --sender). El resultado es que copiará en servidor los archivos ".avi" del directorio actual utilizando como transporte una sessión SSH. En servidor debe existir el usuario mon, el directorio sueltos y la autenticación será la que exija la sesión SSH. Los archivos se depositarán en el directorio sueltos y la copia se realizará como mucho a 10kbytes/seg. |
El remoto es servidor
Este modo se establece porque requerimos el objeto remoto mediante la especificación servidor:módulo/objeto.Por una parte, en el servidor, como root defino en /etc/rsync.conf los módulos que quiero, por ejemplo:
[programas] | Definimos el módulo programas. |
path = /home/pepe/prgs | Su directorio raíz es éste y forzamos chroot que mejora la seguridad, el cliente no tiene por qué saberlo. |
read only = no | Permitimos escritura. |
uid = pepe | Este es el usuario y el grupo del servidor con que rsync accederá a los archivos, el cliente no tiene porqué conocerlo. |
auth users = manolo | Este es el usuario que debe poner el cliente, la contraseña en el archivo /etc/rsyncd.secrets. |
rsync -avcP *.c manolo@servidor::programas/mios/ | Copiará manteniendo los permisos y demás, combrobando checksum y mostrando progreso los archivos ".c" del directorio actual
a la máquina servidor.
Al especificar el módulo programas, se requiere manolo como identificación. Debe de existir en el servidor el directorio /home/pepe/prgs/mios, que es donde se copiarán los archivos. |
rsync -avP -e ssh *.c pepe@servidor::programas/mios/ | Conectará con el servidor por SSH, usuario pepe, y entonces arrancará en remoto una instancia de rsync en modo servidor (--server --daemon). En este caso usar un usuario propio de Rsync no tendría sentido, por lo que es conveniente que, al ser a nivel de usuario y no de sistema, rsyncd.conf esté en el directorio HOME del usuario pepe y no requiera ninguna autenticación extra, ya que la autenticación ha sido por SSH. |
[programas] | Éste podría ser el aspecto del fichero rsyncd.conf del usuario pepe. No puede usar chroot, pues es una operación privilegiada del administrador, pero el funcionamiento es el mismo, chroot sólo es una medida de seguridad extra. Como he comentado, no es necesario un fichero de autenticación ni especificar un usuario propio de Rsync, pues el usuario es pepe y se ha autenticado vía SSH. |
command="rsync --server --daemon --config=rsyncd.conf ."de modo que cuando se autentique con su llave se ejecuta ese comando. En rsyncd.conf de mi HOME debo colocar:
[ejemplo] | El cliente sólo podrá acceder a cosas. No puedo usar chroot porque rsyncd no es ejecutado por el administrador. |
rsync -e ssh yomismo@servidor:: | Le dirá qué modulos están disponibles. |
rsync -e ssh -a yomismo@servidor::cosas/. . | Copiará el contenido del directorio remoto al directorio actual. |
rsync -e ssh -a yomismo@servidor::cosas/.. | No hace caso del .. , sólo conseguirá listar el directorio cosas. |
Notar también que si queremos montar un servidor rsync autónomo, basta con ejecutar: rsync --daemon, pudiendo cambiar el puerto por defecto (873) con la opción --port, y por supuesto el archivo de configuración.
Otros usos ^
La operación de mover un archivo grande de un disco duro a otro implica copia de datos. En el caso de discos IDE usar mvsuele sobrecargar el sistema. Una solución es:#!/bin/bash | Creamos este script del shell que lee la carga del sistema (le quita el punto) y la almacena en la variable l. |
[ $l -le 200 ] && break | Si la carga es menor que dos, sale del bucle, si es mayor espera 5 segundos. |
rsync -aP --bwlimit=5000 "$1" "$2" && rm "$1" | Realiza la copia con un límite de 5Mbytes/seg de velocidad y si todo va bien borra el original. |
dd if=/dev/null seek=102400 bs=102400 count=0 of=ficherocrea un archivo de 10Gigas de tamaño, pero que en el disco ocupa 0 bytes. Si copiamos este archivo con scp, la copia creada, local o remota, sí que reserva todo el espacio en disco, en el ejemplo 10Gigas. Si especificamos la opción -S en rsync, logramos que el rsync remoto respete el uso de disco, de modo que el archivo copiado sólo ocupa los bloques realmente usados en el original, en el caso del ejemplo anterior, ocupará igualmente 0 bytes.
Network File System (NFS) ^
Sistema de ficheros remoto que permite compartir archivos entre un servidor y varios clientes. Se aconseja su uso para redes locales, puesto que la transferencia de todos esos datos puede ser pesada, pese a emplear UDP sobre IP y no TCP.Es importante señalar que está altamente integrado en los sistemas Unix, es decir, que un usuario que use un directorio remoto apenas percibe la diferencia con su sistema local. También que manteniene perfectamente la coherencia del sistema de ficheros, por ejemplo, si desde varios equipos de accede al mismo directorio, y se crea un archivo en él, todos los equipos ven los cambios de forma inmediata. Realmente lo que sucede es que los equipos cliente realizan peticiones RPC al servidor que es quien realiza los cambios, sin generar incoherencias en el sistema de archivos real. Los equipos cliente no perciben el sistema como un "disco" sino como "directorio remoto".
El servidor comparte directorios previamente montados, no importa el tipo de sistema de archivos que se trate. Para compartir un directorio, el servidor debe incluirlo en el erchivo /etc/exports, con el formato:
directorio maquina(opciones),maquina(opciones),...La máquina puede ser una sola o un conjunto determinado por nombre o IP, de modo que *.uji.es significaría todas las máquinas cuyo nombre termine en .uji.es y 192.168.* todas las IPs que comiencen por 192.168. Las opciones más relevantes son rw o ro y no_root_squash. Esta última anula una funcionalidad del NFS por la que los archivos del root del directorio compartido son vistos por el cliente como propiedad de nobody.
El servidor debe tener instalados y en marcha los demonios rpc.mountd y rpc.nfsd, o alternativamente usar el servidor integrado en el kernel. Sólo el administrador puede decidir lo que se comparte, pues debe expresarse en /etc/exports.
El equipo cliente, para poder emplear el directorio compartido, debe montarlo como cualquier otro sistema de archivos, en este caso de tipo nfs, según:
mount -t nfs servidor:directorio_exportado driectorio_localDeducimos que el cliente debe ser administrador y que el tipo de sistema de ficheros nfs debe estar disponible en el kernel.
Como ejemplo, supongamos que tenemos dos equipos administrados por la misma persona y que en ambos están los mismos usuarios. Queremos aprovechar los dos discos de los ordenadores para los distintos usuarios. Para ello el equipo A exporta /home y el equipo B exporta /home2. Los usuarios se crean aleatoriamente en /home y /home2. El equipo B crea el /home vacío y monta el /home de A. El equipo A crea el /home2 vacío y monta el /home2 de B. De este modo un usuario accede al equipo que quiere y accede a sus archivos sin problemas, puede que en local o puede que en remoto, de forma transparente.
Cuestiones del tema ^
for s in 1 2 3 4 5 6 7 8 9; doSi hay espacios en blanco el shell necesita que ponga comillas en el nombre:
ssh -A servidor0 "scp fichero servidor$s;"
done
ssh -A servidor0 "scp 'fichero' servidor$s;"En el caso de hacerlo sin scp es más complejo:
ssh -A servidor0 "ssh servidor$s 'cat >\"fichero\"'" <"fichero"
ssh -fn MAQ2 "while true; do xwd -display :0 -name miVentanita | convert - gif:- \ | ssh MAQ1 'cat >volcado.gif'; sleep 1m; done"1. ¿Por qué -fn ? 2. ¿Por qué las comillas en el cat? 3. ¿Qué pasaría si no las pusiera? 4. ¿Y si pusiera ssh MAQ1 cat \>volcado.gif? 5. ¿Cuándo terminará el
#!/bin/bash
bs=10240
if [ ! "$1" ]; then
echo "$0 host:orig destino"
exit 1
fi
d=${2:-.}
h=${1%%:*}
if [ "$1" = "$h" ]; then
echo host:fichero
exit 1
fi
f=${1#$h:}
if [ -d "$d" ]; then
d="$d/${f##*/}"
fi
ta=$(ssh -n "$h" "find '$f' -printf '%s'")
ta=$[ta]
if [ $ta -eq 0 ]; then
echo fichero "$1" inexistente, inaccesible o vacío
exit 1
fi
if [ ! -f "$d" ]; then
dp="${d%/*}/.${d##*/}.$(date +%s)$$"
trap "mv '$dp' '$d'" exit
# aquí empieza lo importante
dd bs=1 seek=$ta count=0 if=/dev/null of="$dp" 2>/dev/null
n=$[ta/20/bs+1]
for ((i=0; i<ta/bs; i+=n)); do
ssh -n "$h" "dd if='$f' bs=$bs skip=$i count=$n 2>/dev/null" |
dd conv=notrunc bs=$bs seek=$i of="$dp" 2>/dev/null &
sleep 5;
done
wait
# hasta aquí
trap exit
mv "$dp" "$d"
fi
rsync -e ssh -a -p "$1" "$d"
- ¿qué hace cada ssh del bucle for?
- ¿por qué sleep 5?
- ¿cuántos ssh puede llegar a haber a la vez?
- ¿qué objetivo puede perseguir tantos ssh simultáneos?
- ¿para qué el rsync al final?
- si lo pruebas, este script no te funcionará sobre al.nisu.org. cambia sleep 5 por sleep 60 y prueba a ver.
rsync -e ssh -aP MAQ:archivo .nos trae el archivo de la máquina remota. Explica qué hace el comando:
rsync -e "ssh MAQ" -aP "":archivo .y por qué ¿Podrías forzar un strace de ambos rsync?
Razona lo que hace el comando
rsync -e "ssh -A MAQ_INT ssh" -aP MAQ:archivo .y por qué es necesaria la opción -A. Lo mejor para entenderlo es que lo pruebes.
eval $(ssh-agent) ssh-add ssh -A B ssh C comando
command="ls" ssh-rsa AAAAB............PPsKEZk= pepito@jame
Si uso rsync, deberé usar un bucle en cada ordenador, pues los archivos no estarán enteros. Es realmente complejo, porque además, rsync usa nombres de archivo temporales imprevisibles. Podria ser algo como:
ord_ant=elmio ln -s fichero temporal.$$ for ord in otro_ord otro_mas ... ; do ssh -f $ord " while true; do rsync -L -e ssh -a --partial $ord_ant:temporal.$$ fichero & sleep 1m [ -f .fichero.* ] || break rm -fs temporal.$$ ln -s .fichero.* temporal.$$ wait done rsync -e ssh -a --partial $ord_ant:fichero . " sleep 2m ord_ant=$ord doneEl script no está probado, así que seguramente tendrá algún error. Parte de que tengo un acceso shell sin password, es decir usando un par de llaves. Aunque no lo he explicado en clase, debería usarse la nueva opción --inplace para evitar estar copiando el archivo continuamente y todo el lío de los links que probablemente acabe fallando.
Un método más fácil parece trocear el fichero en muchos trozos pequeños, y en cada ordenador poner un bucle que transmita todos los archivos pequeños usando rsync. Debe ser un bucle porque igual que antes, comenzaré a transmitir de un ordenador a otro cuando sólo haya un archivo. Puede ser igual de difícil que el otro de implementar y he de calcular cuidadosamente el tamaño del archivo por el retraso inicial inducido. Quizá el mejor método es este:
ord_ant=elmio $tam=$(find fichero -printf %s) for ord in otro_ord otro_mas ... ; do ssh $ord "ssh $ord_ant 'tail -c +1 -F fichero | head -c $tam' > fichero" & done wait for ord in otro_ord otro_mas ... ; do ssh $ord "rsync -e ssh -a --partial --inplace $ord_ant:fichero ." & done waitÉste método aprovecha las características del tail -f que espera incluso a que el fichero exista. El head asegura que el comando terminará. Estos comandos pueden usarse porque el enunciado dice que no hay cortes en la transmisión. El último rsync es sólo para asegurarnos de que ha ido bien.
ini=0 for ord in am1 am2 am3 ; do for ((i=$ini, i<360, i=i+3)); do ssh $ord "dd bs=1024000 if=archivo skip=$i count=1" | dd seek=$i bs=1024000 of=archivo count=1 conv=notrunc done & ini=$[ini+1] doneEl método es malo porque hago 120 ssh a cada ordenador. Puedo hacerlo con 1 ssh a cada uno:
ini=0 for ord in am1 am2 am3 ; do ssh $ord " for ((i=$ini, i<360, i=i+3)); do dd bs=1024000 if=archivo skip=\$i count=1 done" | for ((i=$ini, i<360, i=i+3)); do dd seek=$i bs=1024000 of=archivo count=1 conv=notrunc done & ini=$[ini+1] doneEsto no funciona, averiguar por qué. Una vez resuelto el problema, en cualquier caso me convendría, al final, hacer:
rsync -e ssh -aP am1:archivo .por si acaso.
while ! rsync --bwlimit=8 -aP servidor:archivo . ; do sleep 1m; doneCada vez que se corta rsync, da un error, espera un minuto y reintenta. Cuando acabe con éxito saldrá del bucle. Basta con abrir un terminal en el portátil, poner el bucle y rogar a la familia que no se lo carguen. Si no limito el ancho de banda, se quejarán, a 8kbyt me da tiempo para la descarga.
Si la conexión sufre cortes frecuentes, la cosa está difícil. No puedo usar rsync con las opciones típicas, porque antes de empezar a transmitir datos transmite los md5 de los frangmentos para saber lo que le falta por transmitir, con lo que es posible que en 30 segundos no le de ni tiempo a sincronizar. Puedo forzar a que rsync use bloques para md5 de tamaños grandes, pero forzaré muchas restransmisiones de datos si en la media hora de Internet no se trnsmiten bloques completos. Otra alternativa es usar un bucle con rsync --append y al final, cuando haya descargado, hacer rsync normal con bloque grande por si acaso, ya que el --append da pocas garantías. Nota: para el bucle de rsync necesito autenticación automática, con par de llaves, por ejemplo vía ssh-agent.
Una vez dentro de A hago vncverver para arrancar el servidor VNC. En mi ordenador ejecuto vncviewer localhost:1
Las peticiones al puerto 5901 de mi ordenador se enviarán a A a través de la sessión ssh, por tanto conectaré con el servidor VNC de A. Si el puerto 5901 de mi ordenador no está libre, pero sí lo está por ejemplo el 5905 y en A, al arrancar vncserver me ha asignado el display :2, el comando sería: ssh -L 5905:localhost:5902 miuruario@A y conectaría con vncviewer localhost:5
Método 2: En mi ordenador arranco el visor en modo espera, accedo por ssh a A y allí arranco el server pero que conecte con mi ordenador. Ésto sólo es posible si mi ordenador es accesible desde fuera.
for f in $(<archivo-lista) ; do rsync -aP $f . doneDespués mato el agente con kill $SSH_AGENT_PID
La única consideración de seguridad que debo tener es que mi amigo es totalmente de fiar y no ha hecho nada para copiar la llave privada. En lugar de usar el agente, podría copiar la llave en local y destruirla después, pero es menos elegante.
f=$1; h=$2 bs=10240 ta=$[$(wc -c <$f)] n=$[ta/20/bs+1] # 20 conexiones, pueden ser más for ((i=0; i<ta/bs; i+=n)); do dd if=$f bs=$bs skip=$i count=$n | ssh -n $h "dd conv=notrunc bs=$bs seek=$i of='$f' 2>/dev/null" & done rsync -aP $f $h:Si se quiere evitar la fragmentación del disco remoto, antes del for:
ssh -n $h "dd if=/dev/zero bs=$bs count=$[ta/bs+1] of='$f'"Otra solución, si se dispone de conexión ssh a la inversa, es conectarse al otro ordenador y desde él, traer el fichero justo con el mencionado script.
Soluciones del tipo "lo parto en trozos con rar" no sirven porque no cabe en el destino.
/root/cpsec.sh aRaiz 30 /home /copias
ejecutada periódicamente, donde /root/cpsec.sh es este script:
#!/bin/bash -x
set=$1; shift
dias=$1; shift
bck=${!#}
LANG=es_ES@euro; export LANG
cd ${0%.sh}.d || exit 1
lishoy=$(rsync -aPxu $* --delete -n | sed -ne 's=^deleting ==p');
echo "$lishoy" >$set.$(date +%s)
rsync -axub --suffix=~~$(date +%s) $*
olis=$(find $set.* -mtime +$dias)
[ "$olis" ] || exit
ab=$(find $set.* -mtime -$dias)
(IFS=$'\n'
for f in $lishoy; do
for b in $ab; do
if ! grep -q '^'"$f"'$' $b ; then
continue 2
fi
done
rm "$bck/$f" 2>/dev/null
rmdir "$bck/$f" 2>/dev/null
done)
echo "olis" | xargs -r rm -f
- Explica con palabras qué hace el script.
- Explica cuantas copias viejas puede llegar a haber de un archivo.
- Da un comando que liste las copias viejas.
- Haz un script que haga prácticamente lo mismo con 2 líneas.
- Mantiene una copia idéntica de los directorios origen (en este caso /home) en el destino en este caso (/copias/home). Los archivos borrados o modificados no se borran, sino que se mantienen dirante 30 días, en el caso de los modificados con un nombre diferente, añadiendo al final la fecha en segundos según ~~$(date +%s). Cada vez que se ejecuta el script se guarda una lista de los archivos que deberían ser borrados en ese momento si no se quisieran guardar. Para decidir que un fichero debe ser borrado, se comprueba que está en todas las listas de los últimos 30 días y entonces se borra. La variable set (en el ejemplo aRaiz) se emplea para poder mantener en /root/cpsec.d las listas de diferentes ejecuciones de /root/cpsec.s.
- Si el script se ejecuta n veces al día, se guardan hasta 30*n copias, cosa que sucedería si un mismo archivo se modifica siempre entre dos copias.
- find /copias/ -regex '.*~~[0-9]+'
- Al llamar a rsync con --delete puedo poner un filtro que evite que borre las copias viejas: -f "P *~~*".
Aprovechando que el ctime cambia al renombrar un archivo, el comando find sólo borrará aquellos
archivos renombrados hace más de 30 días y que cumplan el patrón establecido:
#!/bin/bash -x dias=$1; shift bck=${!#} rsync -qaxb --delete --suffix="~~$(date +%s)" -f "P *~~*" $* find "$bck" -regex ".*~~[0-9]+" -ctime +$dias | xargs -d '\n' -r rm -v¿Es idéntico el funcionamiento al del otro script? Suponiendo que el script se invoca cada hora, ¿cómo puedes saber, después de una invocación, qué archivos han sido copiados o renombrados?
El bucle de Rsync es necesario porque el archivo en B va creciendo. Es muy ineficiente, se mejora mucho con --append, para no recalcular la integridad del archivo cada vez, aún así es muy tosco, pero fácil de hacer. Esto responde correctamente a la pregunta.
No obstante, una forma más elegante es: Elijo un puerto en B y C, por ejemplo 4500 y primero ejecuto en C nc -l -p 4500 >archivo de modo que lo que entra por el puerto 4500 se guarda en el archivo. En B ejecuto nc -l -p 4500 | tee archivo | nc C 4500 de modo que lo que entra por el puerto 4500 se guarda en el archivo y se reenvía a C. En A simplemente nc B 4500 <archivo. Lo interesante de está opción es si no tengo acceso a ningún puerto que no se a el SSH, entonces tengo que tunelar: En A ejecuto ssh -fN -L4500:localhost:4500 B y en B ssh -fN -L4500:localhost:4500 C. Con ello ya tengo acceso y ejecuto los comandos anteriores, pero sobre localhost.
rsync -qaxb --delete --suffix="~~$(date +%s)" \ -f "P *~~*" dir_local máquina_remota:dir_contenedor ssh máquina_remota "find dir_contenedor/dir_local \ --regex '.*~~[0-9]+' -ctime +5 | xargs -d '\n' -r rm"
DNS, sistema de nombres de dominios ^
Para referirnos a un ordenador, según hemos visto en el promer tema, especificamos su IP. Pero las funciones que realiza un ordenador o la información que suministra, nada tienen que ver con su IP, por lo que es difícil recordar las IPs de los ordenadores a los que accedemos.Para hacer más intuitiva la identificación de ordenadores, el Sistema de Nombres de Dominio provee la facilidad de asociar nombres a IPs, de modo que es más sencillo recordar, por ejemplo, www.uji.es que su IP, para referirnos al servidor Web de la UJI.
El sistema de nombres de dominios en Internet es un sistema distribuido, jerárquico, replicado y tolerante a fallos. Aunque parece muy difícil lograr todos esos objetivos, la solución no es tan compleja en realidad. El punto central se basa en un árbol que define la jerarquía entre los dominios y los sub-dominios. En un nombre de dominio, la jerarquía se lee de derecha a izquierda. Por ejemplo, en www.uji.es, el dominio más alto es .es. Para que exista una raíz del árbol, se puede ver como si existiera un punto al final del nombre: www.uji.es., y todos los dominios están bajo esa raíz.
Dominios ^
Los dominios se clasifican en función de su nivel o profundidad dentro del árbol de la jerarquía DNS. De este modo existen dominios de primer nivel, segundo nivel, etc. Dentro de Internet, los dominios de primer nivel están gestionados por organizaciones específicas bien definidas, privadas o de carácter gubernamental. Los dominios de segundo nivel, en general, están gestionados por entidades particulares (empresas, individuos, etc.).
No hay límite en la profundidad del dominio. A los dominios de primer nivel se los conoce como TLD (Top Level Domain). En Internet, existen dos tipos de TLD:
- Dominios de Nivel Superior Globales (gTLD)
Creados para ser usados por los usuarios de Internet en general. Tambien son conocidos como Dominios de Internet genéricos. Son usados (al menos en teoría) por una clase particular de organizaciones (por ejemplo, .com para organizaciones comerciales). Tiene tres o más letras de largo. La mayoría de los gTLDs están disponibles para el uso mundial, pero por razones históricas mil (militares) y gov (gubernamental) están restringidos para el uso por las respectivas autoridades estadounidenses. Los gTLDs están subclasificados dentro de los dominios de Internet patrocinados (sTLD), ej. aero, coop y museum, y los dominios de Internet no patrocinados (uTLD), ej. com, net, org. Algunos de los dominios gTLD que se manejan en la actualidad son:- No patrocinado: biz, com, edu, gov, info, int, mil, name, net, org
- Patrocinado: aero, cat, mobi, coop, jobs, museum, pro, travel
- Infraestructura: arpa, root
- Fase de inicio: post, tel
- Propuestos: asia, cym, geo, kid, kids, mail, sco, web, xxx
- Dominios de Nivel Superior de Código de País
En inglés ccTLD, country code Top-Level Domain. Son dominios reservados para un país o territorio. Existen unos 243 ccTLDs, tienen una longitud de dos letras, y la mayoría corresponden al estándar de códigos de países ISO 3166-1. Cada país designa gestores para su ccTLD y establece la reglas para conceder dominios. Algunos países permiten que cualquier persona o empresa del mundo adquiera un dominio dentro de sus ccTLDs, por ejemplo Austria (.at) y España (.es). Otros países y territorios dependientes sólo permiten a sus residentes adquirir un dominio de su ccTLD, por ejemplo Australia (.au), Andorra (.ad) y Canadá (.ca).
Las laxas restricciones de registro para ciertos ccTLDs ha originado nombres de dominio como pagina.de, I.am ('yo soy' en inglés) y go.to ('ir a' en inglés). Otras variaciones en el uso de ccTLDs se han denominado domain hacks, usándose juntos el dominio de segundo nivel y el ccTLD para formar una palabra o título. Esto ha originado dominios como blo.gs de las Islas Georgias del Sur y Sandwich del Sur (.gs), del.icio.us de los Estados Unidos de América (.us) y cr.yp.to de Tonga (.to). (Con este fin también se han usado TLDs no nacionales, como inter.net que usa el TLD genérico .net, probablemente el primero de cuantos se han hecho.)
Tambien es frecuente el uso de ccTLDs con cambio de significado. El caso más famoso es el de .tv que originalmente pertenecía a Tuvalu y fue vendido a VeriSign por US$45 millones y se utiliza para canales de televisión.
El dominio .ws perteneciente a Samoa Occidental (West Samoa) se comercializa como web site. La Federación Micronesia vende su dominio para radios FM. Las Islas Cocos también vendieron su dominio, .cc, a Verisign. Se sugiere que los compradores le pueden dar cualquier significado, como por ejemplo, cámara de comercio, circuito cerrado, centro de conferencias, centro comunitario o country club. El dominio de Yibuti o Djibuti es .dj lo que ha sido utilizado en algunos casos para páginas de disc jockeys. El dominio de Turkmenistán, .tm, se usa conjuntamente para sitios web de dicho país y como abreviatura de trade mark, marca registrada.
- .ac
- Isla Ascensión
- .ad
- Andorra
- .ae
- Emiratos Arabes
- .af
- Afghanistán
- .ag
- Antigua & Barbuda
- .ai
- Anguilla
- .al
- Albania
- .am
- Armenia
- .an
- Antillas Holandesas
- .ao
- Angola
- .aq
- Antártida
- .ar
- Argentina
- .as
- Samoa Americana
- .at
- Austria
- .au
- Australia
- .aw
- Aruba
- .az
- Azerbaijan
- .ba
- Bosnia y Herzegowina
- .bb
- Barbados
- .bd
- Bangladesh
- .be
- Bélgica
- .bf
- Burkina Faso
- .bg
- Bulgaria
- .bh
- Bahrein
- .bi
- Burundi
- .bj
- Benin
- .bm
- Bermuda
- .bn
- Brunei Darussalam
- .bo
- Bolivia
- .br
- Brasil
- .bs
- Bahamas
- .bt
- Bhutan
- .bv
- Islas Bouvet
- .bw
- Botswana
- .by
- Belarus (Bielorusia)
- .bz
- Bélice
- .ca
- Canadá
- .cc
- Islas Cocos (Keeling)
- .cd
- República del Congo
- .cf
- Repúb. Centro Africana
- .cg
- Republica de Congo
- .ch
- Suiza
- .ci
- Costa de Marfil
- .ck
- Islas Cook
- .cl
- Chile
- .cm
- Camerún
- .cn
- China
- .co
- Colombia
- .cr
- Costa Rica
- .cs
- Checoeslovaquia
- .cu
- Cuba
- .cv
- Cabo Verde
- .cx
- Islas Christmas
- .cy
- Chipre
- .cz
- República Checa
- .de
- Alemania
- .dj
- Djibouti
- .dk
- Dinamarca
- .dm
- Dominica
- .do
- República Dominicana
- .dz
- Argelia
- .ec
- Ecuador
- .ee
- Estonia
- .eg
- Egipto
- .eh
- Sahara Occidental
- .er
- Eritrea
- .es
- España
- .et
- Etiopía
- .fi
- Finlandia
- .fj
- Fiji
- .fk
- Islas Malvinas
- .fm
- Micronesia
- .fo
- Islas Faroe
- .fr
- Francia
- .ga
- Gabón
- .gb
- Reino Unido
- .gd
- Granada
- .ge
- Georgia
- .gf
- Guyana Francesa
- .gg
- Islas Guernsey y otras
- .gh
- Ghana
- .gi
- Gibraltar
- .gl
- Groenlandia
- .gm
- Gambia
- .gn
- Guinea
- .gp
- Guadelupe
- .gq
- Guinea Equatorial
- .gr
- Grecia
- .gs
- Islas Georgia del Sur
- .gt
- Guatemala
- .gu
- Guam
- .gw
- Guinea-Bissau
- .gy
- Guyana
- .hk
- Hong Kong
- .hm
- Islas Heard McDonald
- .hn
- Honduras
- .hr
- Croacia
- .ht
- Haití
- .hu
- Hungría
- .id
- Indonesia
- .ie
- Irlanda
- .il
- Israel
- .im
- Islas de Man
- .in
- India
- .io
- Territ Brit. Indico
- .iq
- Iraq
- .ir
- Irán
- .is
- Islandia
- .it
- Italia
- .je
- Islas Jersey
- .jm
- Jamaica
- .jo
- Jordania
- .jp
- Japón
- .ke
- Kenia
- .kg
- Kyrgystán
- .kh
- Camboya
- .ki
- Kiribati
- .km
- Islas Comoros
- .kn
- Saint Kitts and Nevis
- .kp
- Corea del Norte
- .kr
- Corea del Sur
- .kw
- Kuwait
- .ky
- Islas Cayman
- .kz
- Kazakhstán
- .la
- Laos
- .lb
- Líbano
- .lc
- Santa Lucía
- .li
- Liechtenstein
- .lk
- Sri Lanka
- .lr
- Liberia
- .ls
- Lesotho
- .lt
- Lituania
- .lu
- Luxemburgo
- .lv
- Latvia
- .ly
- Líbia Arabe Jamahiriya
- .ma
- Marruecos
- .mc
- Mónaco
- .md
- Moldavia
- .mg
- Madagascar
- .mh
- Islas Marshall
- .mk
- Macedonia
- .ml
- Malí
- .mm
- Myanmar
- .mn
- Mongolia
- .mo
- Macau
- .mp
- Islas Marianas del Norte
- .mq
- Martinica
- .mr
- Mauritania
- .ms
- Montserrat
- .mt
- Malta
- .mu
- Mauricio
- .mv
- Maldivas
- .mw
- Malawi
- .mx
- México
- .my
- Malasia
- .mz
- Mozambique
- .na
- Namibia
- .nc
- Nueva Caledonia
- .ne
- Niger
- .nf
- Islas Norfolk
- .ng
- Nigeria
- .ni
- Nicaragua
- .nl
- Paises Bajos
- .no
- Noruega
- .np
- Nepal
- .nr
- Nauru
- .nu
- Niue
- .nz
- Nueva Zelandia
- .om
- Oman
- .pa
- Panamá
- .pe
- Perú
- .pf
- Polinesia Francesa
- .pg
- Papua Nueva Guinea
- .ph
- Filipinas
- .pk
- Pakistán
- .pl
- Polonia
- .pm
- Saint Pierre Miquelon
- .pn
- Pitcairn
- .pr
- Puerto Rico
- .ps
- Palestina
- .pt
- Portugal
- .pw
- Palau
- .py
- Paraguay
- .qa
- Qatar
- .re
- Reunión
- .ro
- Rumania
- .ru
- Rusia
- .rw
- Ruanda
- .sa
- Arabia Saudita
- .sb
- Islas Solomon
- .sc
- Islas Seychelles
- .sd
- Sudán
- .se
- Suecia
- .sg
- Singapur
- .sh
- Santa Helena
- .si
- Eslovenia
- .sj
- Svalbard y Jan Mayen
- .sk
- Eslovaquia
- .sl
- Sierra Leona
- .sm
- San Marino
- .sn
- Senegal
- .so
- Somalía
- .sr
- Surinam
- .st
- Santo Tomé y Principe
- .su
- Unión Soviética
- .sv
- El Salvador
- .sy
- República Arabe Siria
- .sz
- Swazilandia
- .tc
- Islas Turks & Caicos
- .td
- Chad
- .tf
- Territ. Franceses del Sur
- .tg
- Togo
- .th
- Thailandia
- .tj
- Tajikistán
- .tk
- Tokelau
- .tm
- Turkmenistán
- .tn
- Tunez
- .to
- Tonga
- .tp
- Timor Oriental
- .tr
- Turquía
- .tt
- Trinidad y Tobago
- .tv
- Tuvalú
- .tw
- Taiwán
- .tz
- Tanzania
- .ua
- Ucrania
- .ug
- Uganda
- .uk
- Reino Unido
- .um
- Islas Menores USA
- .us
- Estados Unidos
- .uy
- Uruguay
- .uz
- Uzbekistán
- .va
- Vaticano
- .vc
- S. Vincente Grenadines
- .ve
- Venezuela
- .vg
- Islas Vírgenes UK
- .vi
- VIslas Vírgenes U.S.A.
- .vn
- Vietnam
- .vu
- Vanuatú
- .wf
- Islas Wallis y Futuna
- .ws
- Samoa
- .ye
- Yemen
- .yt
- Mayotte
- .yu
- Yugoslavia
- .za
- Sudáfrica
- .zm
- Zambia
- .zr
- Zaire (Congo)
- .zw
- Zimbabwe
Delegación de autoridad ^
Los dominios de primer nivel correspondientes a los países (ccTLDs) son gestionados por estos a su voluntad. Esto es posible porque estos dominios están delegados en administradores propios al país, de forma que son éstos los que los gestionan. Dicha delegación de autoridad sobre un dominio se puede realizar a cualquier nivel del espacio de nombres, de manera que si una empresa dispone un dominio de segundo nivel, podría crear dominios de niveles inferiores según la estructura organizativa de la empresa.En concreto, la delegación de autoridad consiste en la cesión del control de una zona del espacio de nombres propiedad de un servidor DNS a otro servidor DNS. Una zona es una porción del espacio de nombres, de forma que se posee autoridad desde el nodo raíz de dicha zona dentro del árbol jerárquico, pudiendo crear o eliminar nuevos subdominios a partir del nivel en el que se encuentre dicho nodo raíz.
La base de datos de los DNS es distribuida: el servidor de DNS de nivel 1 delega autoridad en el servidor DNS de nivel 2 y este a su vez al servidor de nivel 3 y así sucesivamente. Para responder a las consultas, se sigue la cadena de delegación. Normalmente los servidores de DNS tienen un archivo con una lista de los servidores de nivel 1 para poder comenzar a buscar. Esta lista se actualiza periódicamente (una vez al año más o menos).
La diferencia entre dominio y zona suele ser confusa en un principio. Se trata de dos conceptos relacionados en diferentes capas: dominio es un concepto del espacio de nombres, mientras que zona es la forma en la que se distribuye la autoridad.
Así pues, un dominio contiene todas las máquinas que están dentro de dicho dominio, incluidos subdominios, mientras que una zona incluye solo las máquinas del dominio que cuelgan del subdominio sobre el que se posee la autoridad. Podría decirse que las zonas son la forma en la que se distribuye el control sobre el espacio de nombres, y, por lo tanto, que son una causa directa de la delegación de autoridad sobre el espacio de nombre.
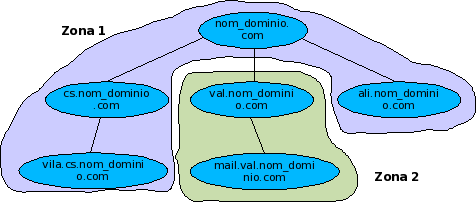 La figura muestra una posible división en zonas de nom_dominio.com.
La zona 1 se compone del propio dominio y de los dominios cs y ali y sus subdominios.
En cambio la autoridad sobre el dominio val que está al mismo nivel que cs y ali,
ha sido cedida a otro NS, con lo que él y sus subdominios pertenecen a otra zona.
La figura muestra una posible división en zonas de nom_dominio.com.
La zona 1 se compone del propio dominio y de los dominios cs y ali y sus subdominios.
En cambio la autoridad sobre el dominio val que está al mismo nivel que cs y ali,
ha sido cedida a otro NS, con lo que él y sus subdominios pertenecen a otra zona.
Resolución directa y resolución inversa ^
Hemos hablado de traducir nombres a IPs. Esto se denomina resolución directa, y es la más frecuente. La resolución inversa, consiste en, dada una IP de Internet, proporcionar el nombre que se le asocia. La resolución inversa se realiza con tablas diferentes a la resolución directa (no consiste en acceder a la misma tabla indexada por una columna diferente), De hecho, si la resolución del nombre nA a la IP I1 la realiza una tabla del servidor ns1, la resolución de la IP I1 puede que la realice otro servidor, con su tabla y el nombre resultante puede no ser nA. Es decir. Además, como vimos enla primera práctica, la relación nombre-IP es de muchos a muchos, produciéndose muchas inconsistencias, aunque a veces son aparentes (ver las cuestiones del tema).Relación entre servidores ^
El proceso de propagación en el DNS consiste en la difusión de los cambios producidos en dominios de los que se tiene autoridad. Este proceso suele tardar entre 24 y 72 horas (tiempo de latencia), aunque en teoría los cambios deberían ser visibles inmediatamente después de haberlos realizado. Este retraso se debe en la mayor parte a las caché que suelen usar los DNS.Existen dos tipos de configuraciones para los servidores DNS: recursivos y no recursivos. Será recursivo si el servidor intenta devolver el resultado exacto de la petición recibida, y será no recursivo en caso contrario (cuando no intenta devolver el resultado exacto). Cuando un servidor no es recursivo, lo que hace es devolvernos la dirección del servidor DNS que posee autoridad sobre el siguiente dominio de la petición que le hemos realizado, de forma que cada vez estamos más próximos al servidor autoritativo. Por tanto, el proceso de resolución de nombres con servidores no recursivos es un proceso iterativo y en el que el cliente participa activamente. Por contra, en el caso de usar servidores recursivos el proceso, desde el punto de vista del cliente, es lineal y con una actuación pasiva. Normalmente no suelen configurarse servidores exclusivamente no recursivos (a excepción de los servidores raíz y de muy alto nivel en el espacio de nombres), sino que suelen actuar como recursivos para un determinado conjunto de nodos y como no recursivos para el resto.
Normalmente los servidores recursivos incorporan una tabla caché, de forma que si se les vuelve a preguntar por un dominio del cual han averiguado su IP y el TTL o Tiempo de Vida de la respuesta no ha vencido, no vuelven a realizar la búsqueda, sino que devuelven el resultado anterior. Cuando la resolución se lleva a cabo de esta forma, el servidor DNS que la realiza indica en la respuesta que 'no es autoritativa'. Una respuesta se considera que es autoritativa cuando proviene del servidor que posee autoridad sobre el dominio en cuestión, siendo no autoritativa para el resto de casos. El tiempo TTL de una respuesta viene teóricamente suministrado por el NS que tiene la autoridad.
Así pues, el problema de que la propagación entre servidores DNS tenga una latencia tan grande se debe a que debemos esperar a que el tiempo de vida de la entrada en caché del dominio venza en todos los servidores, de forma que llegará un momento en que será necesario volver a realizar la consulta al servidor que posee autoridad, de forma que éste nos responderá con la respuesta correcta, la cual, de nuevo será introducida en la tabla caché de los distintos servidores. El tiempo de expiración de la caché depende de las implementaciones del software DNS y de su configuración, aunque por lo normal se suele respetar el tiempo de vida indicado por la respuesta DNS del servidor.
BIND ^
El software Berkeley Internet Name Domain o BIND es el software de DNS que goza de mayor difusión en Internet, especialmente en sistemas Linux/Unix, en los cuales es un estándar de facto. BIND se compone de un programa servidor de nombres, llamado named y de una serie de herramientas de consulta.Para configurar un servidor de nombres es necesario crear un fichero de
configuración (habitualmente /etc/named.conf) en el que se especifican las
opciones del dominio (ubicación de ficheros, recursividad, etc.) y las zonas
definidas en el dominio, así como la ubicación del fichero de configuración de
cada zona.
La información más importante del fichero named.conf se refiere a las declaraciones de zonasi
sobre las que el servidor posee autoridad.
Para una zona, el servidor puede ser primario o secundario (maestro master o esclavo slave).
Un servidor maestro es el que contiene la fuente principal de datos de una zona, que se guarda en un archivo
al que denominamos fichero de zona. Un servidor secundario (para una zona) es aquel que, teniendo autoridad,
toma los datos del maestro periódicamente, de modo que si el maestro falla, el esclavo está disponible.
El esclavo suele guardar los datos en un fichero de respaldo que él mismo construye.
Desde fuera, un maestro y un esclavo son percibidos como servidores con autoridad sobre la zona, es decir
no puede saberse cuál es maestro y cuál esclavo, pues un concepto de BIND.
Veamos cómo es un fichero named.conf a través de un ejemplo:
options {
directory "/var/lib/named";
notify yes;
allow-recursion {
213.171.249.250/32;
192.168.0.0/16;
127.0.0.0/8; };
allow-transfer {
213.171.249.250/32;
80.35.84.125/32;
127.0.0.0/8; };
forwarders {
213.201.48.198;
150.128.81.251; }; |
La sección options establece las opciones de funcionamiento de named. La directiva directory indica donde están los archivos de zona. La directiva allow-recursion lista de grupos de IPs (usando máscaras) para las que éste servidor es recursivo. Para el resto de IPs no será recursivo. La directiva allow-transfer lista de grupos de IPs autorizadas a obtener volcados de las zonas. Suelen ser los servidores secundarios, o aquellos equipos desde los que admitiremos un comando host -l que vimos en la primera práctica. La directiva forwarders, cuando el servidor actúe como recursivo, antes de intentar una resolución por sus propios medios, lista los servidores a los que éste preguntará (obviamente deben ser también recursivos). |
logging {
category lame-servers {
null; }; |
La sección logging establece la cantidad de logs que named registra. En el ejemplo, se establece que no registre nada sobre servidores erróneos encontrados. |
zone "." {
type hint;
file "root.hint"; |
La sección zone declara una zona, su nombre va entre comillas y no necesita el punto final, se presupone. La zona "." es de un tipo (type) especial denominado hint y establece que el archivo especificado con la directiva file contiene la lista de los servidores raíz, necesaria cuando el servidor debe actuar como recursivo (forwarders aparte). |
zone "mobelt.com" {
type master;
file "master/mobelt.com"; |
Para resto de zonas el tipo es master o slave. Para las zonas que se declara maestro, es necesario dar el fichero donde se encuentra la definición de la zona. Para las zonas que se declara esclavo, es necesario dar unalista de IPs de los maestros y, opcionalmente, un fichero de respaldo. |
zone "168.192.in-addr.arpa" {
type master;
file "master/168.192.in-addr.arpa"; |
Este extraño nombre de zona define una zona de resolución inversa. Para ello se usa el sufijo reservado .in-addr.arpa. Los números especificados determinan el rango de IPs para el que estamos definiendo la resolución inversa, en orden contrario. En el ejemplo, 168.192 indica que se va a definir autoridad sobre las IPs 192.168.0.0/16. Obsérvese la escasa flexibilidad para definir la resolución inversa, no pueden especificarse rangos de IPs más detallados. Para resolver el problema, dada la escasez de IPs (IPv4) en la actualidad, se pueden incluir máscaras para refinar la delegación como explica el RFC2317. |
key dyn.mia {
algorithm HMAC-MD5;
secret "gvcn43v518="; |
Ésta es la forma de definir una zona de actualización dinámica. Primero se especifica la llave que permitirá la actualización y en la definición de la zona, se establece que puede ser actualizada dinámicamente y con qué llave. Las zonas de actualización dinámica permiten que su contenido sea modificado sobre la marcha, sin necesidad de recargar el servidor de nombres. |
Ficheros de zona ^
Cada fichero de zona contiene registros de recursos que definen los parámetros de la zona asignando los nombres e ip's en el espacio de nombre de la zona. A diferencia de named.conf, la sintaxis es orientada a líneas. Se pueden escribir comentarios en los ficheros de zona después de los puntos y comas (";").Todos los nombres que se usan en los registros de recursos y que no acaban por un punto (.) se añaden al nombre de dominio.
Los registros de recursos de ficheros de zona contienen columnas de datos, separadas por espacios o tabuladores, que definen estos registros. Si la primera columna está vacía, se asume que es la misma de la línea anterior. Si es @ es sinónimo del nombre de la zona que se está definiendo. Como antes, expliquemos la sintaxis con un ejemplo para la zona mobelt.com:
$TTL 300 |
En la versión 9 de BIND es obligatorio especitifar el TTL de los nombres de la zona mediate una línea de esta forma. |
@ IN SOA mobelt.com. |
Definimos para el propio dominio (@) el registro SOA (Start Of Authority), indicando el nombre del dominio y la dirección de mail de contacto.
A continuación siguen 5 valores entre paréntesis, todos ellos en segundos si no se especifica lo contrario.
El valor serial number debe incrementarse cada vez que cambia el fichero de zona con el fin de que se propagen los cambios a los esclavos.
El valor time to refresh dice a todos los servidores esclavos cuánto tiempo tienen que esperar antes de preguntar al maestro por cambios de zona,
usando entonces el serial number para saber si hay cambios.
La opción time to retry informa al servidor de nombres esclavo sobre el intervalo de tiempo que tiene que esperar antes de emitir una petición de actualización de datos en caso de que el servidor de nombres maestro no le responda. Si el servidor maestro no ha respondido a una petición de actualización de datos antes que se acabe el intervalo de tiempo time to expire responde el servidor esclavo presentándose como servidor con la autoridad en este espacio de nombres. La opción minimum TTL pide a cualquier servidores de nombres que guarde en caché la información de esa zona durante al menos ese periodo. Las unidades de tiempo son segundos pero pueden usarse múltiplos, como m, h, d y w con significados obvios |
IN NS dns.mobelt.com. |
Al comenzar por espacio los registros hacen referencia al mismo que la línea anterior (@) y establecen los NS que sirven a este dominio. Obsérvese el punto al final, teóricamente debe ser un FQDN (full qualified domain name), aunque en la práctica podría usarse un nombre relativo. |
IN A 89.128.67.11 |
El registro de tipo A asigna una IP, en este caso al propio dominio. |
IN MX 10 mail |
Indica que el correo de este dominio es manejado por mail.mobelt.com con prioridad 10, su significado lo veremos en el tema del correo. |
dns IN A 150.128.97.91 |
Totalmente necesario asignarles una IP, puesto que se están usando en la definición de propiedades del dominio. |
www IN A 89.128.67.11 |
Definimos cuantos nombres queramos, en este caso www.mobelt.com y pelis.mobelt.com |
litus IN A 89.128.67.11 |
Definimos si queremos dominio de cuarto nivel en esta misma zona. Además estamos usando la misma IP para todos, no es problema. |
pepe IN NS ns.soypepe.com. |
Perdemos autoridad sobre pepe.mobelt.com, delegándola al servidor especificado. |
otro IN NS ns.otro |
Igual que antes, pero esta vez la delego a un servidor que está dentro de la misma zona delegada, ns.otro.mobelt.com, por lo que debo definir aquí su IP. |
pop IN A 150.128.97.91 |
El servidor POP está muy cargado, definimos dos IPs para él. Nuestro NS las devolverá en orden aleatorio y los clientes normalmente se quedan con la primera de ellas. Así se obtiene un sencillo balanceo de carga. |
* IN A 89.128.67.11 |
Con esto definimos que cualquier nobre no definido previamente en mobelt.com tiene esa IP. |
Resolución inversa ^
Los ficheros de resolución inversa tiene igualmente registro SOA y registros NS. Para definir una IP, basta con especificar por ejemplo, para el archivo 168.192.in-addr.arpa, que hemos especificado anteriormente en nuesto named.conf de ejemplo, un registro PTR que indica el nombre asociado a la IP (debe ser un FQDN).3.30 IN PTR portatil-eth.casa.Acabamos de definir que la IP 192.168.30.3 resuleve al nombre portatil-eth.casa.
La resolución de nombres en un ordenador ^
Cuando abrimos el navegador y accedemos a una página de un servidor usando su nombre, ¿cómo invoca el navegador al NS?. El navegador usa una librería para la conversión del nombre a IP, libresolv, que opera del siguiente modo. En primer lugar consulta el fichero /etc/nsswitch.conf, que normalmente le indica que en las consultas del DNS debe consultar primero ficheros locales y después el DNS. El fichero local consultado es /etc/hosts, un fichero que contiene una tabla de IPs y nombres (relación uno a muchos). Si éste fichero no resuleve la consulta, accede a /etc/resolv.conf que tiene este aspecto:nameserver 1.2.3.4La directiva nameserver indica qué servidores de nombres debe usar, en el orden especificado (consulta al siguiente sólo si uno falla o no da la respuesta). La directiva search indica el sufijo por omisión, es decir, ese sufijo es añadido al dominio buscado.
nameserver 6.7.8.9
search patata.com
Cuestiones del tema ^
pepe IN NS 1.2.3.4Es correcta? Resp.
pepe IN NS dns.pep dns.pepe IN A 1.2.3.4
Por ejemplo, el servidor dns.mobelt.com. tiene autoridad sobre todo el dominio nisu.org, pero mirando este fichero de zona, vemos que contine subdominios de 4 nivel, como *.al, y al mismo tiempo delega autoridad de la zona dyn a otro servidor de nombres, (en este caso coincide ser el mismo), pero en una zona diferente, de actualización dinámica, que es la usada en la práctica del DNS, como puede verse también en el fichero de configuración.
domi. IN NS 150.123.45.67Di todos los errores que hay. Resp.
patata666 IN NS dns1.patata666.comAl borrar patata666.com hay dos posibilidades:
patata666 IN NS dns2.patata666.com
dns1 IN A 1.2.3.4
dns2 IN A 1.2.3.5
- Al borrar patata666.com se borran también dns1.patata666.com y dns2.patata666.com, con lo que jamon666.com queda sin resolución de nombres hasta que le asignemos un nuevo DNS.
- Como jamon666.com depende de dns1.patata666.com y dns2.patata666.com, al borrar patata666.com no se borran los dns. Así jamon666.com sigue funcionando. Esto es absurdo, pues si alquien registra de nuevo patata666.com se creará una contradicción. Nota: esta situación absurda se producjo en el ES-NIC a finales de los 90 con el dominio infc.es, increíble :-)
El correo electrónico ^
El correo electrónico es una de las palicaciones más antiguas de Internet y de las más interesantes, pues a diferencia de la mayoría, el usuario trabaja sin conexión, es decir, que las personas que se comunican no tienen por qué estar simultáneamente conectadas.El correo electrónico se asemeja notablemente al correo postal tradicional. Cuando queremos mandar una carta escrita en papel a alguien, la redactamos tranquilamente en casa, la metemos en un sobre timbrado, escribimos cuidadosamente la dirección del destinatario y la llevamos a una oficina postal para que llegue a su destino. A partir de ahí, los servicos de correo se encargarán de que llegue a su destino. El cartero intentará llegar al destinatario repetidas veces. Si no lo encuentra, la carta volverá al remitente y, si lo encuentra, se pondrá en su buzón. El destinatario la leerá cuando quiera.
Las direcciones de correo
Evidentemente necesitamos especificar de alguna forma quién es el destinatario de nuestros envíos. Debemos considerar que puede ser cualquier persona con el adecuado acceso a Internet. Las direcciones de correo tienen la forma nombre@dominio. Por nombre entendemos normalmente la identificación de una persona, pero puede representar otras figuras (p.e. un programa). Este nombre pertenece a un dominio, que puede ser cualquier domnio válido. Hablamos de dominio en el sentido general, es decir un dominio propiamente dicho o una máquina determinada.Las direcciones se pueden expresar, para mayor intuitividad, en la forma: descripción <nombre@dominio>. La descripción es ignorada por los servicios postales, pero permite mayor claridad para el usuario. Realmente la dirección que va entre < y > puede ser más complicada, algo de la forma <@dominio1,@dominio2:nombre@dominio>. Aquí se especifica la ruta (relays)por la que ha de pasar un correo, es decir que en lugar de intentar ir al destino final directamente, deberá pasar por los manejadores de correo de los dominios previamente especificados. Para comprender correctamente estas ideas es necesario conocer el funcionamiento real del correo.
Funcionamiento ^
 Cuando queremos enviar un correo a alguna dirección redactamos el mensaje mediante el
programa adecuado, denominado agente de usuario de correo (MUA),
escribimos la dirección del remitente y le pedimos al programa que lo envíe. El MUA conecta entonces con un agente de transporte (MTA),
siguiendo el modelo cliente-servidor. Se establece un diálogo SMTP, que es el protocolo usado para el envío del correo, por el que el MUA
le indica al MTA el remitente y el destinatario, que constituyen el envoltorio.
Cuando queremos enviar un correo a alguna dirección redactamos el mensaje mediante el
programa adecuado, denominado agente de usuario de correo (MUA),
escribimos la dirección del remitente y le pedimos al programa que lo envíe. El MUA conecta entonces con un agente de transporte (MTA),
siguiendo el modelo cliente-servidor. Se establece un diálogo SMTP, que es el protocolo usado para el envío del correo, por el que el MUA
le indica al MTA el remitente y el destinatario, que constituyen el envoltorio.
El MTA, que suele estar en un ordenador diferente del de usuario, intenta enviarlo al destinatario, que es otro MTA, emplendo SMTP. Si no puede conectar con el MTA destino, no es problema. EL MTA mantiene una cola de mensajes salientes donde se encuentran los mensjaes que no se han podido enviar. Periódicamente procesa la cola e intenta enviar los mensajes. Si pasan varias horas sin conseguir enviar un mensaje, se manda un aviso al remitente (si así está configurado). El MTA intenta enviar el mensaje durante varios días y si no lo consigue, envía un error al remitente y deja de intentarlo. Lo habitual en la práctica es que mensajes pequeños llegan en pocos minutos.
Para el agente de transporte es importante saber a qué ordenador debe entregar el mensaje. Esta información la obtiene del DNS. Toma el dominio de la dirección destino y si el DNS:
- sólo le indica una IP, conecta con esa IP.
- le indica un registro de mail (MX), ignora la IP y conecta con el ordenador indicado en el registro MX.
- le indica varios registros MX, intenta con el de mayor prioridad (valor más bajo). Si no puede conectar, intenta el siguiente y así sucesivamente.
Depositado el mensaje en el buzón, el usuario destinatario, para leerlo, debe acceder al buzón. Puede que tenga acceso directo sobre el sistema de archivos, pero eso no es lo habitual. Lo normal es que el destinatario emplea un ordenador propio para leer el correo y conecta con el ordenador que "tiene" los buzones con algún protocolo específico, como son POP3 e IMAP.
SMTP básico ^
El transporte básico de mensajes SMTP (Simple Mail Transfer Protocol) es el estándar para el intercambio de mensajes utilizando el protocolo TCP/IP y esta definido en el RFC 2821. En temas de seguridad, la autenticidad es escasa y la confidencialidad nula; en cambio la disponibilidad (puedo mandar un correo independientemente de que destinatario esté conectado o no) y la integridad (los cortes de red no le afectan) son mayores que en los demás servicios.Actualmente está definido el ESMTP (SMTP extendido), mucho más complejo, pero podemos ver las bases de SMTP con un ejemplo:
telnet mail.mobelt.com 25 |
Conectamos con un MTA, puerto 25. El prgrama telnet nos permite realizar una sesión SMTP a mano. |
220 ESMTP mobelt |
El MTA responde con un código numérico y un mensaje. Esta numeración sigue un estándar que está presente en otros protocolos:
|
helo mobelt.com |
Saludamos. Si el saludo es con el comando ehlo indicamos que solicitamos ESMTP. |
mail from: prueba1@nisu.org |
Especificamos el envoltorio, la direción del remitente. Muchos MTA realizan muy diversas medidas anti-spam, por ejemplo, comprueban si existe el dominio del remitente. |
rcpt to: prueba2@mobelt.com |
Dirección de destino. Ahora se aplican reglas de relaying. |
data |
Indicamos que vamos a introducir el mensaje, el MTA nos dice que debemos terminarlo con una línea conteniendo sólo un punto. |
Subject:ejemplo smtp |
El mensaje. |
250 2.0.0 Ok: queued as A74C14D5BF |
El MTA ha aceptado el mensaje para reparto local (en este caso) o para reenvío. Lo encola, y normalmente lo procesa inmediatamente. |
quit |
Con este comando terminamos la sesión y el servidor nos desconecta. |
Relays, spam ^
Hemos comentado que el correo electrónico imita el correo tradicional en papel. Pero hay una diferencia clara: para enviar un mensaje no es necesario pagar, a diferencia del correo en papel, que cada carta lleva su timbre con un coste.Esta pequeña diferencia, que supuso una gran ventaja económica en los primeros años de Internet, justamente ha resultado en cierto nivel de caos en el correo electrónico, pues muchas empresas envían correo no deseado a millones de destinatarios, es el denominado spam. Igualmente, virus y troyanos envían masivamente correo, de modo que entre virus y spam suponen más del 50% del correo que circula.
En la línea de imitar el correo tradicional, históricamente, los MTA de Internet estaban abiertos para dar servicio a cualquiera, a usuarios y a otros MTAs, pero esto era el paraíso para los spammers, que usaban los MTA para disponer de colas gratuitas para los reintentos. El spam ha hecho que estos relays abiertos hayan desaparecido y actualmente los MTA utilizan unas reglas para decidir a quien dan servicio, es decir para quién actuan como relay. El algoritmo correcto es el siguiente:
- Si el receptor es local (es uno de los dominios para los que tengo buzones)
- Aceptar
- Si no
- Si la IP del cliente está autorizada
- Aceptar
- Si no
- Si el cliente se autentica
- Aceptar
- Si no
- Rechazar
Además de este control imprescindible, los MTA toman medidas antispam, entre las que cabe mencionar:
- Consultar la IP del cliente en listas de spammer (como spamcop).
- Rechazar las tripletas (IP cliente,dirección origen, dirección destino) desconocidas con un error 4XX, forzando que el cliente reintente. Si es un MTA legítimo, reintentará, y entonces la tripleta se almacena en una base de datos de modo que no vuelve a rechazarse a no ser que no se produzca la tripleta en bastante tiempo, por ejemplo 3 días. Esta técnica se denomina greylisting.
- Analizar el contenido de los mensajes para detectar spam. Esto es bastante delicado, pues se dan falsos positivos. Las técnicas más usadas son la búsqueda de indicios (ciertas palabras, estructura del mesnaje, etc.) y el análisis estadístico (bayesiano).
- Uso de marcas de autenticidad de los servidores. La más sencilla es el SPF, que es un campo de texto (IN TXT) que se coloca en el DNS e indica, explicado muy simplemente, qué servidores están autorizados para mandar correo con un determinado dominio remitente (ejecuta host -t txt nisu.org para ver un ejemplo). Otro caso de marca de autenticidad es el que emplea gmail, denominado DKIM-Signature, que es una verdadera firma digital realizada por el servidor de correo saliente y que se incluye como un campo en la cabecera del correo (para ver un ejemplo, basta con ver el "código fuente" de un correo que nos envien desde gmail).
POP3, IMAP, Webmail ^
Cuando el propietario de un buzón desea leer el correo que hay en él, necesita acceder al buzón de alguna manera. Los protocolos POP3 e IMAP dan este servicio. POP3 es un protocolo adecuado para que podamos bajar todo el correo de golpe, aunque puede bajar los mensajes uno a uno. Se emplea principalmente en conexiones con módem en las que el tiempo de conexión cuesta dinero. De las posibilidades que el POP permite, los agentes suelen ofrecer:- Bajar todos los mensajes y borrarlos del servidor.
- Bajar sólo los no leídos y no borrar ninguno del servidor. Podrá borrarlos selectivamente después.
Para observar las limitaciones del protocolo, veamos cómo es una sesión básica POP:
telnet anubis.uji.es pop3 |
Conectamos a un servidor POP3 mediante telnet. |
user mollar |
Proceso de autenticación. La contraseña se envía en claro. |
list |
Solicitamos la lista de mensajes. Nos devuelve los mensajes numerados, normalmente en el orden en que están en el buzón, indicando el tamaño de cada uno. Obsérvese que no conocemos ni remitent, ni asunto, etc. |
retr 3 |
Obtenemos el mensaje número 3 y lo borramos. |
quit |
Desconexión. |
IMAP es más potente y eficaz, pero su uso es sólo conveniente cuando el coste de la conexión no va en función del tiempo y podemos estar
leyendo los mensajes mientras estamos conectados. La gran ventaja del IMAP es que los mensajes están siempre en el servidor.
Cuando el agente se conecta, obtiene la lista de las cabeceras de los mensajes y las muestra al usuario. Éste puede entonces ver asunto y remitente
y ello le permitirá leer selectivamente los mensajes y no tener que esperar a traer mensajes largos. Incluso si un mensaje lleva distintos objetos
MIME (adjuntos), IMAP bajará (descargará del servidor) sólo la lista de objetos, pudiendo el usuario seleccionar cuáles quiere ver.
Otra facilidad importante de IMAP es que permite manejar múltiples buzones auxiliares en el mismo servidor. Estos buzones los define (los crea)
el usuario y los utiliza para clasificar los mensajes que quiere guardar. IMAP permite mover un mensaje de un buzón a otro, de modo que al leer el
buzón principal (denominado usualmente buzón de entrada, Inbox en inglés), el usuario va enviando los mensajes a los distintos buzones.
De hecho, los agentes potentes permiten clasificar automáticamente los mensajes recibidos simplemente al acceder al buzón de entrada.
Para ello se especifican unos criterios (reglas) que en base a los campos de la cabecera determinan a qué buzón auxiliar han de enviar los mensajes.
Una descripción detallada del protocolo excede los limites de este documento.
Lo que acabamos de describir es familiar para los usuarios habituales de Wbmail (gamil, hormail, yahoo, etc.). Realmente lo que sucede es que un Webmail no es más que un cliente SMTP e IMAP que en lugar de estar instalado en nuestro servidor, corre en un servidor Web. EL usuario se conecta con su navegador a ese servidor Web, que corre una aplicación web que es cliente de algún servidor SMTP y de algún servidor IMAP.
Agentes de transporte ^
En el mundo Un*x, el primer MTA que fue ampliamente utilizado fue Sendmail. Su presencia llegó a ser universal, pero tenía graves problemas de seguridad por estar programado con escaso cuidado, aparte de utilizar internamente un esquema suid en lugar de un esquema cliente-servidor. Actualmente otros MTAs como Postfix, Exim, o Qmail presentan mayor estabilidad aun sin alcanzar la versatibilidad de la configuración de Sendmail.Todos estos MTAs, aparte de realizar las funciones requeridas que hemos explicado al describir los fundamentos del correo, aportan otras funcionalidades requeridas por los complejos sistemas de correo:
- Permiten especificar filtros aplicables al correo y basados en diversos criterios
- Disponen de complejos esquemas de tablas que permiten especificar operaciones específicas para correos específicos. Por ejemplo, una tabla de transporte que en función por ejemplo del dominio destino, podrá elegir un relay distinto. Estas tablas pueden ser almacenadas de distintos modos, incluso contra motores de base de datos como MySQL.
echo test | sendmail alguien@dominio.comenviará un correo conteniendo sólo la palabra test a esa dirección de correo. Como veremos en breve, todo correo debe tener una cabecera. El programa sendmail añadirá una cabecera mínima a ese correo, donde sólo figurará el remitente que obtendrá de los datos del usuario que ejecuta el comando y del nombre de la máquina donde lo ejecuta. La ejecución de:
echo $'Subject: prueba\n\nHola' | sendmail -f yo@midominio.com alguien@dominio.comenviará un correo con "asunto" y con remitente cambiado a yo@midominio.com. En ambos ejemplos es interesante observar que el destinatario no se incluye en la cabecera, lo que viola el RFC822, pero permite enviar el mismo correo a varios destinatarios de un golpe.
Formato del mensaje ^
Un mensaje se compone, como hemos indicado, de un envoltorio, que controlan los agentes de transporte, más un contenido que se divide en una cabecera y un cuerpo que viajan juntos y están relacionados.iCabeceras
La cabecera es una parte con fines de control. Se compone de una serie de líneas y se separa del cuerpo por una línea en blanco. Cada una de sus líneas tiene la estructura: campo: valor. Si una línea comineza en blanco se entiende continuación de la anterior. Los campos más relevantes de una cabecera son:- To: Indica el destinatario del mensaje. Obligatorio, aunque si no se especifica los MTA lo admiten.
- Cc: Lista de las direcciones de correo que recibirán una "copia de carbón del mensaje" (Copia Identica). Opcional.
- Subject: Describe el contenido del mensaje (asunto).
- Date: Indica fecha y hora en que envió el mensaje (según el emnisor).
- Reply-To: Especifica la dirección a la que el remitente desea que se le conteste. Este campo es opcional.
- Return-path: Dirección de retorno en caso de que el envío falle.
- From: Dirección del correo del remitente y posiblemente su nombre (en la forma descrita antes).
El campo Bcc es un campo de los clientes de correo, no del protocolo. Insta al cliente a añadir direcciones destino en el envoltorio sin incluirlas en la cabecera.
Podemos inventarnos campos en la cabecera, respetando el estándar, simplemente precediendo su nombre por X-, por ejemplo X-Loop: si.
MIME ^
El cuerpo del mensaje es el contenido en sí. No obstante el estándar de correo permite a los MTA cambiar el contenido según su conveniencia sin alterar el significado, de modo que sólo pueden emplearse caracteres ASCII de 7 bit y sólo a partir del código 32 (el espacio), aunque actualmente la mayor parte de agentes admiten 8 bit (otros 128 caracteres). Es decir el mensaje debe ser sólo texto sencillo. Además las líneas del mensaje no deben sobrepasar 1kbyte, se recomienda usar líneas de 72 caracteres. Si no se respetan estas reglas (que también se aplican a la cabecera), el MTA puede, literalmente, destrozar el cuerpo del mensaje.Estas restricciones impiden enviar objetos no-texto a través del correo, pues inicialmente se concibió para texto simple. A medida que se detectó la necesidad de enviar otros objetos, como imágenes, en lugar de alterar el comportamiento de los MTA que hubiera sido un caos, se optó por buscar métodos de codificación para convertir objetos binarios a texto. Un método clásico en Un*x fue uuencode. Algunos clientes como Eudora optaron por sus propios formatos, en este caso muy ineficientes, pues la conversión de binario a texto implica un aumento de tamaño que debe ser lo menor posible.
La solución definitiva es el estándar MIME. Su uso permite que se puedan intercambiar a través del correo todo tipo de contenidos. Además, una parte importante del MIME está dedicada a mejorar las posibilidades de transferencia de texto en distintos idiomas y alfabetos. MIME va a implementar el concepto ofimático de adjunto (que no es un componente del correo), de modo que un texto puede ir acompañado de una imagen y además el receptor será informado de que es una imagen y de como ha sido codificada para poder decodificarla y tratarla (por ejemplo mostrarla) debidamente.
En primer lugar, un mensaje MIME se identifica por la presencia en la cabecera del mensaje del campo: MIME-Version: 1.0. El único campo que es obligatorio es el que indica el tipo de contenido del mensaje: Content-Type: tipo/subtipo. Los tipos MIME están estandarizados (aunque mediante x- pueden añadirse nuevos). A modo de ejemplo citemos:
- text/plain: texto común, sin formato. En los tipos texto suele indicarse el juego de caracteres empleado.
- text/html: texto HTML
- application/pdf: un archivo PDF. El tipo es application porque los PDF son propios de ciertas aplicaciones.
- application/octet-stream: tipo genérico que indica binario desconocido, es decir una serie de bytes generados por alguna aplicación.
- multipart/mixed: un mensaje que se compone de varias partes MIME, como explicamos a continuación.
- message/rfc822: el contenido es otro mensaje de correo, con sus propias cabeceras y cuerpo. Se emplea para correos literalmente reenviados.
- 7bit: tal cual, sin codificación.
- quoted-printable: sólo se codifican los caracteres no compatibles con 7bit, cada uno se codifica con un signo = seguido de dos dígitos hexadecimales del caracter a codificar. Debe emplearse cuando hay pocos caracteres a codificar, pues por cada caracter codificado tripica el espacio usado.
- base64: como un binario es base 256, se realiza un cambio de base a 64, empleando un conjunto de 64 carcateres que se imprimen perfectamente. Como 2^8=256 y 2^6=64, incrementa en 8/6=4/3 el tamaño de un objeto, es decir un 33%. Debe emplearse en objetos calramente binarios, como imágenes, videos, etc.
/usr/sbin/sendmail <<-EOF tudireccion@tudominio Subject: prueba MIME-Version: 1.0 Content-Type: text/plain; charset=iso-8859-1 Content-transfer-encoding: base64 aG9sYQo= EOFte enviará el saludo hola. Tu lector de correo sabrá que es texto sencillo y lo mostrará tras decodificar el base64.
Cuando el tipo MIME es multipart, el cuerpo del mensaje se compone de varias partes, delimitadas por un separador.
Cada una de las partes es como un pequeño mensaje, debe tener su cabecera con su tipo MIME y su cuerpo. El tipo de cualquiera
de las partes puede ser otro multipart, con lo que se crea una estructura recursiva en forma de árbol de profundidad arbitraria.
Normalmente los lectores de correo realizan un recorrido infijo del arbol a la hora de mostrarlo al usuario.
El multipart más corriente es el multipart/mixed, que representa una serie de partes formalmente inconexas.
Este tipo es el que se emplea para implementar el concepto ofimático de adjunto: cuando mandamos un mensaje con un programa
de correo y adjuntamos una foto, realmente se crea un multipart/mixed con dos partes, un texto y una imagen.
Realmente el concepto de adjunto no existe a nivel MIME. El formato del mensaje lo podemos ver con un ejemplo:
MIME-Version: 1.0 Content-Type: multipart/mixed; boundary=unafraseunica ***Lo que va aquí debe ser ignorado por el lector de correo.*** --unafraseunica Content-Type: text/plain; charset=iso-8859-1 Content-Transfer-Encoding: quoted-printable Este mail lleva una peque=F1a imagen --unafraseunica Content-Type: image/gif; name="sound2.gif" Content-Transfer-Encoding: base64 Content-Disposition: inline R0lGODlhFAAWAMIAAP///8z//8zMzJmZmWZmZjMzMwAAAAAAACH+TlRoaXMgYXJ0IGlzIGlu IHRoZSBwdWJsaWMgZG9tYWluLiBLZXZpbiBIdWdoZXMsIGtldmluaEBlaXQuY29tLCBTZXB0 ZW1iZXIgMTk5NQAh+QQBAAABACwAAAAAFAAWAAADUBi63P7OSPikLXRZQySmGyF6UCgKV8md m/FFHHqRVVvcNOzdSt7sr4CPMRS6VC8bsmcADIrMT/M5VBo3QYkzh81ufTce0Zph7sqMcBDN XiQAADs= --unafraseunica--Como se aprecia el separador se precede por dos guiones -- y el último además termina con dos guiones. Es importante observar el espaciado: el cambio de línea antes del separador se ignora, es decir, forman parte de la parte MIME anterior todos los cambios de línea que hay antes del separador menos el último. En el ejemplo, la parte text/plain no tiene ningún salto de línea al final.
Algunos agentes, al componer un texto que se desea enviar, pueden emplear facilidades propias de las páginas web, es decir, que componen el mensaje exactamente como una página web, utilizando para ello el lenguaje HTML. Pero puede que este mensaje no lo pueda leer cualquier otro agente, con lo que optan por enviar tanto una versión HTML como una versión texto, y que el receptor elija la que más le convenga. Esto se consigue especificando el tipo multipart/alternative, que se estructura exactamente como el multipart/mixed. Es decir, las partes que contiene un multipart/alternative llevan todas la misma información, el MUA elije una u otra en función de sus habilidades.
Otra costumbre habitual es enviar verdaderas páginas web que contienen imágenes, que también van incluidas en el correo y no deben mostrarse como adjuntos, sino incrustadas en el mensaje. Este efecto se consigue con el tipo multipart/related, que indica que sus distintas partes están relacionadas y deben interpretarse como un todo. Para relacionar las partes, éstas llevan un campo Content-ID:<identificador> y que se referencia especificando la URL cid:identificador. Por ejemplo en el caso de una página web con dos imágenes, el mensaje multipart/related tendrá tres partes, una de ellas text/html que será la página web, que referenciará a las imágenes con <img src="cid:un_dentificador">. Las otras dos partes MIME serán las imágenes, cada una con su identificador. Puede verse un ejemplo en los apéndices.
Por último mencionar el multipart/signed, empleado para realizar firma electrónica (S-MIME) y cifrado de datos.
El objeto de los mensajes cifrados es que sólo el receptor autorizado pueda leer el contenido del mensaje, tan sólo quedaría en
claro el Subject del mismo. Se implementa mediante un objeto PKCS7, cuya estructura excede el ámbito de este documento, y
su tipo MIME es application/x-pkcs7-mime (ver apéndices.).
El objeto de los mensajes firmados es garantizar el origen del
mensaje, mediante la firma electrónica del emisor. La implementación puede realizarse simplemente mediante un objeto PKCS7, pero
el resultado sólo podría leerlo alguien que dispusiera de un lector con capacidad criptográfica. Por ello, usualmente un mensaje
firmado es un multipart/signed que se compone de dos partes, la primera es el mensaje y la segunda la firma electrónica
de la primera parte, es decir del mensaje que queremos firmar. Pueden verse los detalles en el apéndice.
Cuestiones del tema ^
@ IN MX 10 mail.pepito.com mail IN A 192.192.192.192Si mandamos un correo a jate@pepito.com, ¿a dónde irá a parar?. Resp.
echo "user lukas pass pelucas dele 1 quit" | netcat localhost 110Resp.
rar .... opciones de rar para que fragmente .... fichero for f in ficheros_fragmento; do (formail -I 'X-mio: envio'; uuencode $f) | sendmail dirección doneEl receptor puede acumularlos en un buzón filtrando con procmail:
:0 *^X-mio: envio estebuzony después:
formail -s uudecode <estebuzon unrar ....Otra forma de hacerlo es usar el tipo MIME message/partial, soportado por ejemplo por Outlook express. Mediante un programa como el mismo Outlook o el clásico splitmail, el mail inicial de mas de 260 megas se cortará en trozos que serán automáticamente recompuestos en el cliente cuando estén todos. No obstante convendría comprimir el archivo antes de mandarlo, con la intención no sólo de reducir espacio, sino sobre todo de dar un mecanismo de verificación de la integridad del material recibido.
Personalmente prefiero el primer método, aunque sea algo más engorroso, porque si alguno de los archivos rar se corrompiera o se perdiera, puedo construir archivos pequeños de paridad y mandárselos para que pueda reconstruir el original. Las versiones recientes de rar permiten construir archivos de paridad o puedo emplear el programa par2 (freeware). Además, muchos antivirus rechazan el tipo message/partial por no poder scanear el archivo.
- Método malo: a midominio.com le pongo como primer MX mail.midominio.com que el DNS resuelve a la IP 192.168.1.2. Y pongo como segundo MX el ordenador de mi amigo, el nombre que resuelva a la IP pública, no a la privada. Le pido a mi amigo que haga relay de midominio.com. Cuando alguien me mande mail, no podrá conectar con 192.168.1.2, lo mandará al segundo MX que me lo reenviará a 192.168.1.2. El método no es muy bueno porque se producirán timeouts, pero es muy fácil de configurar y cualquier servidor de correo lo permite.
- Método correcto: el servidor de correo de mi amigo permite configurar un mecanismo de transporte para que el correo que recibe a midominio.com lo reenvie a mi ordenador. Entonces pongo para midominio.com un único MX apuntando a la IP pública del ordenador de mi amigo, y él comfigura su ordenador para dicho reenvío, aparte de activar el relay.
if [ "$1"]; then sendmail -f yo@miemail.com -F "Mi nombre" $* <mail.txt sleep 1m else cat destinatarios | xargs -r -n 100 $0 fi
- Por qué las imágenes en el correo se codifican en base64 y no en quoted/printable.
- Por qué las imágenes en el correo se codifican en base64 y no se mandan sin codificar.
- En base64 el tamaño se multiplica por 1.3, en quoted puede ser hasta por 3.
- Los servidores de correo pueden cambiar los caracteres de control, con lo que la imagen quedaría destrozada, además no todos soportan líneas de longitud indefinida.
IN A 1.2.3.4 IN MX 10 mail1 IN MX 10 mail2 mail1 IN A 1.2.3.4 mail2 IN A 1.2.3.5Si enviamos un correo a una dirección de ese dominio, ¿qué servidor de correo la acabará recogiendo? Explica las consideraciones importantes que afectan a los buzones de este sistema de correo. Resp.
for ((i=0; i<30000; i++)); do al=al$(printf "%06d" $i) sendmail $al@anubis.uji.es < fichero_con_el_mail doneEl problema es que mando 30000 mail, lo que me agota el caudal de salida y además el servidor de correo pasará el antivirus y antispam, etc. 30000 veces. Puedo mejorarlo bastante enviándolos de 100 en 100, por ejemplo:
ma=''; c=0 for ((i=0; i<30000; i++)); do ma=$ma" "al$(printf "%06d" $i)@anubis.uji.es c=$[c+1] if [ $c = 100 ]; then sendmail < fichero_con_el_mail $ma c=0; ma='' fi doneComo recibiré muchos correos de error, puedo incluir un campo X-tarari en la cabecera que pongo en fichero_con_el_mail y cuando me devuelva los errores, filtrarlos; o poner un Return-path que sea una dirección con buzón /dev/null.
export SPLITSIZE=1000000 tar zcvf - archivos | mail destinoAunque lo más intuitivo es usar un compresor que parte archivos como por ejemplo rar:
rar a -vn -v1000 -ep trozos.rar archivos for f in trozos.r*; do mutt -a $f destino; doneLas consideraciones previas son: una que el tamaño máximo por correo es al menos de 1.3 megas y la otra que en el buzón del usuario caben los 100 megas a no ser que aplique un filtro que vaya guardando los ficheros aparte, con lo cual lo que necesitará es una quota de disco suficiente.
host -t mx dominio_de_mail_de_mi_amigoy hago
(echo "helo este_ordenador" sleep 1 echo "mail from: mi_dir_correo" sleep 1 echo "rcpt to: dir_de_mi_amigo" sleep 1 echo data sleep 1 uuencode fichero primer_mx_del_destino 25Si veo que los sleep no son suficientes, siempre puedo usar telnet y cortar y pegar con paciencia.
echo test | /usr/sbin/sendmail amigo@sudominio.com
¿Qué diferencia interna hay entre estar usando el verdadero sendmail o el clon que incorpora postfix? Resp.
- Primero hay que configurar N para que reciba el correo de D. Para ello basta con indicarle al MTA que D es uno de sus dominios. En el caso de Postfix puede conseguirse modificando la directiva mydestination e incluyendo D. Dicha directiva está en main.cf.
- Rcargar el servidor de correo.
- Modificar el DNS de A, cambiando el MX que apunta a C, haciéndolo apuntar a N, es decir, donde estaba @ IN MX 10 C ahorá estará @ IN MX 10 N. Al (4) recargar el DNS el correo empezará poco a poco a entrar en N.
Nota: La migración de los buzones es un tema más complejo.
El World Wide Web ^
El world wide web (WWW) es un servicio tan universal en Internet, que iincluso el usuario final denomina la operación "abrir el navegador" como "entrar en Internet". Desde las simples páginas informativas de los años noventa a las complejas redes sociales del presente la evolución tecnológica y conceptual ha sido significativa. En este documento intentaremos dar un vistazo a las tecnologías actuales, pero sólo podremos dar una breve descripción. Nuestro objetivo será realmente fundamentar los aspectos básicos del WWW.El WWW nace en el CERN, que produce un primer servidor muy sencillo y un navegador en modo texto que muestra páginas escritas en HTML, lenguaje de marcas que descibiremos aquí. La aparición de Mosaic, funcionando en entorno X-window supone un avance decisivo al funcionar con el ratón y ser capaz de mostrar imágenes en el propio docuemento. El relevo es tomado por Netscape que desarrolla un potente navegador, líder durante algunos años. El peso que el WWW adquiere en las comunicaciones tal que Microsoft desarola su navegador (Explorer) que desbanca a Netscape. Actualmente Mozilla (Firefox) ha tomado el relevo de Nescape y Google ha entrado en el mundo de los navegadores con Chrome. No obstante Opera sigue siendo el más rápido y eficiente pese a que su uso es marginal. Los navegadores actuales son herramientas muy complejas, inconcebibles sin la potencia de los actuales ordenadores personales. La presentación de HTML4 sólo es una anécdota dentro de las capacidades del navegador, capaz de ejecutar aplicaciones con su intérprete de javascript (y con plugins como flash o applets de java), que junto con las capacidades de los servidores, convierten al navegador en una herramienta casi universal para el trabajo en el PC.
El origen del concepto del Web es la posibilidad de leer un documento que contiene referencias a otros documentos y pasar a leerlos directamente, incluso si están en otros servidores. Es lo que se conoce como hipermedia, un concepto anterior a Internet pero que alcanza su desarrollo con ella.
Para poder referenciar a un documento externo, se introduce el concepto de URL.
El lenguaje PHP
El lenguaje PHP es un lenguaje interpretado de alto nivel que puede ser incrustado dentro de un documento HTML y ejecutarse en el servidor. Es el lenguaje más utilizado en servidores web, y tiene una gran facilidad para trabajar con bases de datos sin demasiados problemas, lo que lo ha hecho muy atractivo para el desarollo web. Además al ser un lenguaje interpretado y con una sintáxis poco complicada, hace que el tiempo de desarrollo de un programa que queramos que ejecute nuestro servidor, sea muy corto, comparado con otros lenguajes como C.La sintáxis tiene muchas características del C, además de ser un lenguaje no tipado, en el cual no es necesario declarar previamente las variables. Una vez una variable es de un tipo, por ejemplo de los arrays asociativos que ofrece el lenguaje PHP, debe utilizarse como ese tipo.
A la hora de incrustar un código PHP dentro de una página web, necesitamos las etiquetas especiales <?php y ?> que delimitarán el trozo de código que hayamos incluido. Hoy en día el intérprete lenguaje está incluido en el propio servidor web Apache lo que lo hace más rápido y totalmente integrado, de modo que es el propio servidor quien interpreta el código PHP cuando procede.
PHP ofrece ayudas para el desarrollo web como las variables $_GET, $_POST en las que encontramos los campos que se han pasado en la URL o por la petición HTTP POST, normalmente procedente de un formulario. La variable $_REQUEST contiene la combinación de $_GET, $_POST y las cookies.
La variable $_SESSION facilita una manera de mantener la información referente a una sesión del cliente, al que se envía una cookie con el identificador de la sesión. El valor de la cookie es el fichero en el servidor donde se está guardando la información de sesión, de modo que al devolver la cookie al servidor, éste recupera lo guardado en la $_SESSION. Para activar las sesiones es necesario llamar a la función session_start() que crea la sessión si no existe la cookie o usa la que ésta le indica. Dado que la función modifica las cabeceras, es necesario llamarla antes de escribir nada en el output.
Para conocer más sobre PHP es recomendable leer éste documento.
Ejemplos de scripts PHP
Veamos pequeños fragmentos de código relacionados con operaciones que es capaz de hacer el PHP. Primero escribiremos un script que coje los datos enviados desde un formulario y los almacena en base de datos.
if ( $_POST['Password'] != $_POST['VerifPassword'] )
die("<h4>Debes de introducir correctamente la password<h4>");
$con = mysql_connect("usuario","servidor","password");
mysql_select_db("baseDeDatos",$con);
$sql="INSERT INTO Usuarios VALUES(";
foreach(array("Nombre","Login","Password") as $cmp) {
if (!get_magic_quotes_gpc())
$_POST[$cmp]=mysql_real_escape_string($_POST[$cmp]);
$sql.="'".$_POST[$cmp]."', ";
}
$err = mysql_query("$sql)",$con);
if ( $err )
echo("<h4>Ha habido un error en la inserción<h4>");
else
echo("<h4>La inserción se ha realizado con éxito.<h4>");
Veamos cómo usar las sesiones:
session_start();
$con = mysql_connect("usuario","servidor","password");
mysql_select_db("baseDeDatos",$con);
foreach(array("usuario","password") as $cmp)
if (!get_magic_quotes_gpc())
$$cmp=mysql_real_escape_string($_POST[$cmp]);
if ( mysql_num_rows(
mysql_query("SELECT * FROM Usuarios WHERE nombre = '$usuario' and password = '$password'"))) {
$_SESSION['login'] = $usuario;
header("Location: aplicacion.php");
die();
} else {
echo("<h4>Usuario y/o contraseña incorrectos.<h4>");
}
A la hora de desarrollar en PHP se hace interesante saber que cuenta con dos lineas de apoyo al desarrollador, en las cuales se incorporan librerias de funciones. Existen dos filosofías en el desarrollo de librerías para PHP. Una es PECL que son extensiones programadas en C que se añaden directamente al intérprete PHP. Ofrecen gran velocidad de ejecución y permiten realizar funciones que no podrían implementarse en PHP. La otra es PEAR que son clases programadas en PHP y deben incluirse mediante la directiva require_once que incluye todo el código del fichero referenciado, teniendo que comprobar sintácticamente el intérprete de PHP todo ese código además de nuestro script. Aún así, dada la gran velocidad de los procesadores actuales, PEAR es muy interesante.
Cuestiones del tema ^
- Redirección http a través de las cabeceras usando el campo Location .
- Redirección usando un campo <meta http-equiv=refresh .
- Usando javascript u otro lenguaje de scripting.
<? $f=fopen('contador','r');
$co=fread($f,400);
fclose($f);
$co=$co+1;
echo $co;
$f=fopen('contador','w');
fwrite($f,$co); fclose($f);
Mejora el script para no tener que abrir el archivo dos veces.
if ($que=$_POST['saca']) { consulta $que; muestra resultados }
else if ($autenticado)
echo "<form method=post>Nombre de quien quieres los datos:",
"<input name=saca><input value=Enviar></form>";
else
echo "Debes autenticarte para acceder a esta página";
Resp.<a href="/busqueda.php?ID=4043">Albengibre</a> <a href="/busqueda.php?ID=4044">Alatoz</a>Y al pinchar en esos enlaces sí que me sale la ficha del pueblo con la información que yo quiero.
Di cómo harías para bajar de un tirón las fichas de los 8110 municipios de España. Resp.
for ((i=1; i<8111; i++)); do GET "LAWEB/busqueda.php?ID=$i" >"pueblo$i.html" done
<? session_start(); echo "Las visitas a esta página son: ".($_SESSION['contador']++);Resp.
telnet al.nisu.org 80 GET / HTTP/1.1 Accept: text/htmlproduce un:
HTTP/1.1 400 Bad RequestExplica por qué. Resp.
En cambio, en el web la sesión se implementa completamente por software de aplicación, puesto que las conexiones TCP normalmente se abren y se cierran continuamente, incluso a veces para la carga de cada uno de los objetos de una página.
Una forma muy fácil de hacerlo es la siguiente. En la salida de mi script (HTML) incluyo un frame o iframe de tamaño 0 que llame a mi script con un parámetro tal que mi script sólo refresca la sesión, no hace nada más, pero la salida del script fuerza la recarga cada 5 minutos (usando Location en la cabecera, o meta+refresh o javascript en el HTML de mi iframe).
El fichero se envía por POST con codificación multipart, que produce algo similar a un correo.
<? $mens="Ye! Mensajes gratis usando la URL http://tonto.com/sms?tel=666777888&". "msg=El+mensaje+que+quieres+mandar"; echo "http://tonto.com/sms?tel=666777888&msg=".urlencode($mens);El resultado es: http://tonto.com/sms?tel=666777888&msg=Ye%21+Mensajes+gratis+usando+la+URL+
http%3A%2F%2Ftonto.com%2Fsms%3Ftel%3D666777888%26msg%3DEl%2Bmensaje%2Bque%2Bquieres%2Bmandar
<form action=reg.php>Nuevo usuario: <input name=user><br> Contraseña: <input name=pass><br>Repite contraseña: <input name=pass2><br> <input type=submit value=Enviar></form>Explica e implementa un ataque trivial que puede hacerse sobre el portal. Explica qué habría que cambiar en el portal para evitarlo. Resp.
while true; do p=ABCabc$RANDOM; GET "http://portal/dir/reg.php?user=usu$RANDOM$RANDOM&pass=$p&pass2=$p"; doneEn este tipo de formularios debe incluirse siempre un CAPTCHA para evitar la automatización.
<form method=post action="x.exe?v1=33"><input name=z><input type=submit></form>
¿Qué encontrará el programa x.exe en la entrada estándar? ¿y en la variable de entorno QUERY_STRING? Resp.
Cuestiones generales ^
- En primer lugar determinaré si el nombre empresa.com está registrado. Si lo está prepararé una lista de alternativas y la contrastaré con la dirección de la empresa.
- Determinado el nombre del dominio, lo registraré en el registrar más adecuado, actualmente Godaddy. Registraré el dominio a nombre de la empresa; como contacto administrativo quien me indique la empresa y lo mismo con el contacto de pago, siendo yo el contacto técnico y usaré para ello direcciones de correo en el dominio recién registrado.
- No colocaré DNS alguno, sino que lo solicitaré aparcado.
- Como sólo tengo una IP, buscaré alguien que quiera actuar de secundario (slave) de mi dominio, que puede ser un colega o una empresa que dé estos servicios, en cualquier caso solicitaré autorización a la dirección para usar un recurso externo.
- Instalaré el SO en el ordenador que me han asignado y el software necesario (DNS, mail, web).
- Configuraré mi DNS y lo daré de alta como, por ejemplo, ns0.empresa.com. Cuando esté registrado, cambiaré el dominio de aparcado a activo y especificaré mi DNS y el otro que he conseguido.
- Comprobaré que en unos días, desde máquinas externas ya se resuelve el nombre empresa.com a mi IP.
- Simultaneando estas tareas administrativas, configuraré el servidor de correo, creando las direcciones de correo que la dirección de la empresa me indique y haré una página web sencilla inicial. El DNS sólo especificará como MX a este ordenador.
- Contactaré con dirección para obtener los requerimientos de la página web de la empresa, y si es necesario contactaré con un diseñador y realizaré la programación necesaria.
- Primero bajare el TTL del DNS al mínimo.
- Haré un primer rsync del servidor viejo al nuevo, que tardará bastante, varios días: Son 30*1024*8 Megabits, que al dividir por 3600 son 68 horas.
- Mientras configuraré el servidor web nuevo para que vaya idéntico o mejor que el viejo.
- Haré otro rsync que debe tardar menos.
- Haré un tercer rsync que casi no tardará nada. No creo que haga falta un cuarto rsync.
- Apagaré el servidor web originial, no el ordenador, ahora no hay servicio.
- Un último rsync que espero sea rapidísimo, y al mismo tiempo:
- Cambiaré el DNS, para que las peticiones vayan al nuevo ordenador y dejaré el TTL como toca.
- Encenderé el nuevo servidor web.
- Montaré el nuevo ordenador e instalaré el operativo y el servidor web.
- Prepararé la configuración del nuevo servidor web idéntica a la original.
- Asignaré al nuevo servidor una ip diferente.
- Mediante rsync transferiré los datos de un servidor a otro. Tardará unos minutos o unas horas dependiendo del tipo de ethernet, pero no será mucho.
- Arrancaré el segundo servidor web.
- Pararé el primer servidor web. No hay servicio.
- Haré un segundo rsync.
- Apagaré el primer ordenador.
- Pondré al nuevo ordenador la ip del antiguo.
Apéndices
Ejemplos de configuración clásica de redes ^
Red segmentada
Vamos a dividir una clase C 194.1.2.0 en dos partes, 194.1.2.0/25 y 194.1.2.128/25. Es la forma más sensata de dividirla, puristas abstenerse. Un equipo con dos interfaces (B) conecta las dos subredes.| A | C |
|||||||||
| 194.1.2.2 |
194.1.2.130 |
|||||||||
| 194.1.2.3 |
194.1.2.131 |
|||||||||
| 194.1.2.1 |
||||||||||
| B | ||||||||||
| 194.1.2.5 |
194.1.2.129 |
194.1.2.132 |
||||||||
| eth0 |
eth1 |
Configuración de A:
ip a a 194.1.2.2/25 dev eth0 |
Estamos en la situación estándar. Sólo debemos añadir una ruta a la otra mitad de la red. |
ip r a 194.1.2.128/25 via 194.1.2.5 |
La ruta siempre es por una IP directamente alcanzable. He configurado 3 rutas, debe ser igual en todos los equipos. |
Configuración de B:
ip a a 194.1.2.5/25 dev eth0 |
Por el lado eth0 es un equipo normal en una red con salida a Internet. |
ip a a 194.1.2.129/25 dev eth1 |
Por el eth1 es lo mismo pero sin salida por ahí. Total 3 rutas. |
Configuración de C:
ip a a 194.1.2.130/25 dev eth0 |
Es un equipo normal con salida a Internet. |
Red segmentada a través de una red privada ^
Ahora la red del ejemplo anterior se divide pero se conecta a través de la red privada 192.168.0.0/24, como muestra la figura.| A | D | E | |||||||||||||
| 194.1.2.2 |
192.168.0.2 |
194.1.2.129 |
194.1.2.130 |
||||||||||||
| eth0 |
eth1 | ||||||||||||||
| 194.1.2.3 |
192.168.0.3 |
194.1.2.131 |
|||||||||||||
| 194.1.2.1 |
|||||||||||||||
| B | C |
||||||||||||||
| 194.1.2.5 |
192.168.0.1 |
192.168.0.4 |
194.1.2.132 |
||||||||||||
| eth0 |
eth1 |
Configuración de A:
ip a a 194.1.2.2/25 dev eth0 |
Es un equipo en red (1 ruta) con salida a Internet (+1=2). |
ip r a 192.168.0.2/24 via 194.1.2.5 |
Además debe acceder a la red privada (+1=3) |
ip r a 194.1.2.128/25 via 194.1.2.5 |
Y a la otra mitad de la red (+1=4). |
Configuración de B:
ip a a 194.1.2.5/25 dev eth0 |
Por el lado eth0 es un equipo corriente (2 rutas). |
ip a a 192.168.0.1/24 dev eth1 |
Por el eth1 está la red privada (+1) |
ip r a 194.1.2.128/25 via 192.168.0.2 |
Y por ahí accede también a la red 192.1.2.128 . |
Configuración de C:
ip a a 192.168.0.4/24 dev eth0 |
Pertenece a la red privada, no hay ruta por defecto. Este equipo carece de acceso a Internet. |
ip r a 194.1.2.0/25 via 192.168.0.1 |
Accede además a las dos mitades de la red 194.1.2.0 |
Configuración de D:
ip a a 194.1.2.129/32 dev eth0 |
Queremos tener una ruta por defecto para este equipo porque dispone de un IP válida
en Internet y porque hace de router de las red .128. Sin lo que se ha marcado en itálica, este equipo actuará estupendamente
como router para los de la red 194.1.2.128. En cambio, si queremos que la ruta por defecto sirva para sus propios intereses, es necesario lo
marcado en itálica. Primero asignamos en eth0 la misma ip que tiene en el interfaz eth1. Esto puede que no sea necesario. Lo que si es importante es que en la ruta por defecto se especifique que la IP de origen es la pública |
Configuración de E:
ip a a 194.1.2.130/25 dev eth0 |
Es un equipo normal conectado a Internet que aprovecha la ruta por defecto para alcanzar
las demás redes. |
ADSL sin NAT
Aunque los routers ADSL suelen hace NAT, ésta es una configuración sin NAT, para un solo equipo detrás del router. El router del proveedor de acceso a internet tiene la IP 217.125.124.193 y la IP pública que se nos ha asignado es la 217.125.124.220. Entre los suministradores de ADSL este esquema suele denominarse configuración monopuesto. La IP pública se asigna a A, que puede además disponer de una IP en la red local. Para que el resto de la red local tenga acceso a internet será necesario que A realice SNAT En nuestro caso hemos dotado a A de dos IP, de modo que es muy fácil pasar al modo multipuesto (con NAT en el router) sin tener que cambiar nada en B.Lo interesante es la configuración del router. En la parte externa, podemos colocar al router la IP que deseemos, porque la comunicación entre el proveedor de la línea y nuestro router no depende de esa IP: el router T envía los paquetes destinados a 217.125.124.220 a través de la línea ATM y al llegar al router son simplemente encaminados hacia la otra interfaz. En la parte interna del router colocamos la misma IP que tiene T. A verá a R como si fuera T. Los paquetes con destino externo se desean enviar a T, y son recogidos por R que los encamina hacia T.
| A | |||||||
| 192.168.0.1, 192.168.0.2 |
|||||||
| T |
R |
217.125.124.220 | |||||
| 217.125.124.193 | 192.168.254.254 | 217.125.124.193 | |||||
| B |
|||||||
| 192.168.0.3 | |||||||
Configuración de A:
ip a a 192.168.0.2/24 dev eth0 |
|
ip a a 217.125.124.220/32 dev eth0 |
¿Podría poner ip a a 217.125.124.220/29 dev eth0 ? |
iptables -t nat -A POSTROUTING -s 192.168.0.0/16 -j MASQUERADE |
SNAT para la red local realizado usando MASQUERADE, puede usarse SNAT |
iptables -t nat -I PREROUTING -p tcp --dport 8088 \ |
Añadido: DNAT: los accesos a A en *:8088 se redirigen a 192.168.0.3:8088 |
Configuración de B:
ip a a 192.168.0.3/24 |
Uso de proxyarp.
Supongamos un edificio con despachos en que cada despacho sólo dispone de una toma de red para conectar un equipo. En el despacho donde está el ordenador señalado en la figura como A quiero conectar otro equipo, B, para lo que aprovecho que A tiene dos tomas de red y con un cable cruzado los conecto.| 194.1.2.2 |
||||||||||
| A |
B |
|||||||||
| 194.1.2.3 |
192.168.0.1 |
194.1.2.23 |
||||||||
| eth0 |
eth1 |
|||||||||
| 194.1.2.1 |
||||||||||
| 194.1.2.4 |
||||||||||
| eth0 |
Configuración de A:
ip a a 194.1.2.3/24 dev eth0 |
Por el eth0 es un equipo en red normal. |
ip a a 192.168.0.1/32 dev eth1 |
Le ponemos la IP que nos apetezca, una privada mejor. Podríamos ponerle tb la 194.1.2.3.
La máscara es /32 porque realmente no existe la red. |
ip r a 194.1.2.23 dev eth1 |
Decimos que B es directamente alcanzable por el cable cruzado. |
ip nei add proxy 194.1.2.23 |
Decimos a la red 194.1.2.0 que nosotros tenemos esa IP, de modo que nos llegarán a nosotros los paquetes con destino a B. |
Configuración de B:
ip a a 194.1.2.23/32 dev eth0 |
Por el lado eth0 es un equipo corriente, pero sin red local. La IP 192.168.0.1 es directamente alcanzable por la eth0 y es la ruta por defecto. |
Configuración de una interfaz wifi
Después de lenvatar la interfaz (sea wlan0) y antes de asignar IP, es necesario conectar con el punto de acceso.iwlist wlan0 scan |
Busco puntos de acceso dentro del alcance, y elijo el que queremos, sea su essid el_essid |
iwconfig wlan0 essid el_essid |
Asigno el essid |
iwconfig wlan0 key 1234567890 |
Si se necesita contraseña WEP, la pongo |
iwconfig wlan0 ap 00:22:2D:42:DE:F3 |
Asocio al punto de acceso elegido |
Ejemplos de configuración moderna de redes ^
NAT
Supongamos una red como la de la figura:| R1 |
A | |||||
| 192.168.0.2 |
||||||
| 192.168.0.3 | ||||||
| R2 |
R |
|||||
| 194.1.2.1 |
192.168.0.1 |
|||||
| 192.168.0.4 | ||||||
Sólo R tiene acceso a Internet, pues los demás ordenadores tienen IP privadas. Podrán acceder a Internet a través de R a nivel de aplicación (proxys por servicio) pero no a nivel de IP. Esta es una situación normal cuando contratamos por ejemplo una conexión ADSL que sólo nos provee de una IP pública. Sería deseable no obstante que los ordenadores de la red local (privada) pudieran acceder a internet en condiciones por lo menos similares a las de R.
Para ello, R, con el software adecuado, hace los siguiente: los paquetes que proviene de la red R1 con destino hacia Internet, son modificados, de modo que la IP origen es sustituida por la IP pública de R, es decir un paquete que va por ejemplo de A (192.168.0.2) a 1.1.1.1 es modificado por R de modo que cuando sale de R la IP origen es la 194.1.2.1 . De este modo, el paquete llega a su destino es atendido y el paquete de retorno llega correctamente a R, a la IP 194.1.2.1. R reconoce el paquete como que fue manipulado, y lo vuelve a manipular "deshaciendo" la operación anterior: sustituye la IP destino por 192.168.0.2 y encamina el paquete a su destino (A) De esta forma A tiene la percepción que está bien conectado a Internet (aunque sólo como cliente). Esta manipulación se denomina SNAT (Source Network Address Translation). En las conexiones TCP, UDP, etc, el paquete que sale de A tiene asociado un número de puerto origen. R intentará mantener el número del puerto origen, pero tendrá que cambiarlo si, por ejemplo, otro ordenador de la red ya usa el mismo socket (está conectando con el mismo servidor remoto, mismos puertos origen y destino). También sucede en algunos software de SNAT que si el puerto origen de A es menor que 1024 (privilegiado) es sustituido por uno no privilegiado, lo que imposibilita el uso de comandos especiales como rsh.
Varios encaminadores por defecto ^
La especificación de varias rutas por defecto en el encaminamiento clásico implica que se usa siempre la primera salvo que el router esté inaccesible, con lo que se emplea la segunda, etc. Pero si tenemos varias líneas y queremos aprovecharlas, podemos desear usar varios encaminadores simultáneamente. Para ello podemos usar el comando ip:. En la red de la figura, podemos configurar A como:ip rout add default equalize \
nexthop weight 10 via 212.95.203.73 \
nexthop weight 10 via 213.171.69.249
| R1 |
|||||
| 212.95.203.73 | |||||
| A |
|||||
| 213.171.69.250 | |||||
| R2 |
212.95.203.76 | ||||
| 213.171.69.249 | |||||
Esta configuración va ligada con la situación que se presenta a continuación.
Selección de ruta ^
Supongamos la red de la figura anterior. Supongamos que el encaminador R1 es el que uso normalmente, y la configuración de A es:
ip a a 213.171.69.250/29 dev eth0 |
Sólo se utiliza el encaminador R2 |
ip r a 150.128.81.252 via 212.95.203.73 |
Establezco una ruta explícita al ese equipo por el encaminador R1 |
ip a a 213.171.69.250/29 dev eth0 |
La IP "principal" es la 76. Sólo se utiliza el encaminador R2 |
|
Establezco una ruta explícita al ese equipo por el encaminador R1 y le fuerzo a usar la segunda IP. |
ADSL con NAT en el router ^
Esta es una configuración típica de un router ADSL que realiza SNAT.El router del proveedor de acceso a internet tiene la IP 217.125.124.193 y nuestro router R tiene la IP pública que se nos ha asignado, 217.125.124.220 , de modo que configuramos con esos parámetros el interfaz externo.
El router provee SNAT a una red local, que es la 192.168.0.0/24. En la interfaz local del router ponemos la IP 192.168.0.1, que pertenece a dicha red local, y activamos SNAT.
Cada uno de los equipos de la red local tendrá una IP de esa red y como ruta por defecto la IP 192.168.0.1. Esta es la configuración que aparece en la figura sin considerar la IP en itálica. Entre los suministradores de ADSL este esquema suele denominarse configuración multipuesto.
En el equipo A decidimos instalar algunos servicios, como un servidor web. Debemos instruir al router para que realice DNAT sobre A, para todos los puertos o selectivamente (recomendable por seguridad). También querremos acceder a esos servicios desde la red local, pero si queremos hacerlo sobre la IP pública, deberemos acceder al router que nos encaminará a A. Pero nos encontramos con que la mayoría de routers no van a realizar primero el SNAT y luego el DNAT. La solución es poner a A la IP pública 217.125.124.220, e instruir al resto de los equipos de la red local para que la busquen en la red local (o vía 192.168.0.2).
| A |
|||||||
| 192.168.0.2 |
|||||||
| T |
R |
217.125.124.220 | |||||
| 217.125.124.193 | 217.125.124.220 | 192.168.0.1 |
|||||
| B |
|||||||
| 192.168.0.3 | |||||||
Configuración de A:
ip a a 192.168.02/24 dev eth0Configuración de B:
ip a a 217.125.124.220/32 dev eth0
ip rou add default via 192.168.0.1
ip a a 192.168.0.3/24
ip rou add default via 192.168.0.1
ip rou a 217.125.124.220 dev eth0
Varios proveedores ^
En la figura se muestra un ejemplo en el que se dispone de varios proveedores de acceso a internet. En el encaminamiento clásico, A sólo puede tener una ruta por defecto. La configuración de A sería:
ip a a 212.95.203.76/24 dev eth0 |
Coloco las 2 IP, que pone las dos rutas en la tabla main
y le doy una ruta por defecto cualquiera. |
ip r a 217.125.124.220/32 dev eth0 table R1 |
Las mismas rutas en dos tablas,
no es estrictamente necesario. |
ip r a default via 212.95.203.73 table R1 |
En cada tabla una ruta por defecto. |
ip rule add from 212.95.203.76 table R1 |
Cuando un paquete salga de la IP 212.95.203.76 mirará en la tabla R1 para decidir cómo enrutar, y elegirá la ruta por defecto correspondiente. El comportamiento será análogo para la IP 213.171.69.250 |
Un ejemplo real.
La red se compone de dos segmentos, uno con cuatro servidores, sean A,B,C y D y otro con uno, X.El router R1 es un router que realiza sólo NAT. La IP pública es 80.59.218.92 y la red local se configura como 192.168.0.202. El router realiza:
- SNAT de los equipos de la red local hacia fuera
- DNAT por puertos desde fuera hacia los equipos de la red local, de modo que el 192.168.0.102 recibe la redirección de smtp, 192.168.0.112 la de http, 192.168.0.132 la de DNS y 192.168.0.122 la de POP3
El equipo D tiene una segunda interfaz de red que le conecta a un punto de acceso wireless con la IP 192.168.0.152, que, configurado como bridge, se comunica con otro idéntico con IP 192.168.0.153, que está en el otro segmento de la red local, donde se conectan el equipo E y el router R4.
Desafortunadamente el router R4 tiene configurada la red "Red X" como 213.171.69.248/29, es decir, que espera encontrar por ejemplo la IP 213.171.69.252 en dicha red, pero no es cierto que estén ahí físicamente, solo están el equipo D y el X. No podemos cambiar la configuración de ese router.
| 192.168.0.102, 192.168.0.103 |
A - smtp |
|||||||||||||||
| 212.95.203.77, 213.171.69.252 | ||||||||||||||||
| R1 |
80.59.218.92, 80.24.139.239 | X |
||||||||||||||
| 80.59.218.92 | 192.168.0.202 | 213.171.69.250 | ||||||||||||||
| 192.168.0.112, 192.168.0.113 |
B - www |
192.168.0.1 | ||||||||||||||
| 213.171.69.253, 212.95.203.76 | R4 |
|||||||||||||||
| R2 |
80.59.218.92, 80.24.139.239 | 213.171.69.249 | ||||||||||||||
| 80.24.139.239 | 192.168.0.203 |
|||||||||||||||
| 192.168.0.132, 192.168.0.133 |
C -DNS |
|||||||||||||||
| 213.171.69.251, 212.95.203.74 | ||||||||||||||||
| R3 |
80.59.218.92, 80.24.139.239 | |||||||||||||||
| 212.95.203.73 | Red X |
|||||||||||||||
| 192.168.0.122, 192.168.0.123 |
D - pop3 |
P1 |
wireless |
P2 |
||||||||||||
| 80.59.218.92, 80.24.139.239 | 213.171.69.254 | 192.168.0.152 |
192.168.0.153 |
|||||||||||||
| 212.95.203.75 |
bridge |
Configuración de A:
ip a a 192.168.0.102/24 dev eth0 |
En primer lugar lo
situamos en su red local y decidimos que el router R1 sea su ruta por
defecto. Esto es posible porque el router hace SNAT. |
ip rout add default via 192.168.0.202 table R1 |
Realizamos la misma
operación en la tabla R1 y creamos una regla para que use la
tabla. |
ip a a 80.59.218.92/32 dev eth0 |
Le colocamos la IP pública del router a la propia máquina., como hicimos en el caso del ADSL con NAT en el router |
ip a a 192.168.0.103/24 dev eth0 |
Lo mismo para el router ADSL R2 |
ip a a 212.95.203.77/29 dev eth0 |
Este es un router sin DNAT, la
configuración es sencilla. |
ip a a 213.171.69.252/27 dev eth0 |
La ruta por defecto que lleva a
R4 es el servidor D que actua de router. |
ip rule add to 192.168.0.0/24 lookup main |
Esto es necesario para que todo
el tráfico a la red interna de la empresa se despache por la
tabla principal de enrutado y no emplee otras reglas previamente
especificadas. |
Configuración de B:
ip a a 192.168.0.112/24 dev eth0 |
Es idéntico a
A |
Configuración de D:
ip a a 192.168.0.123/24 dev eth0 |
Todo esto
está claro. |
ip a a 213.171.69.254/29 dev eth1 |
Configuramos la IP del interfaz
eth1 |
ip rule add to 192.168.0.0/24 lookup main |
Esto es como antes. |
for t in R4 main; do |
La red 213.171.69.248/29 está definida en eth1, pero realmente los equipos estan en la interfaz eth0, lo indicamos. |
ip neig add proxy 213.171.69.252 dev eth1 |
Y hacemos proxyarp para que el
router R4 los encuentre en su red local, donde espera encontrarlos
según la máscara especificada en su configuración. |
Configuración de X:
ip a a 213.171.69.250/29 dev eth0 |
De lo más
normal. |
ip r a 212.95.203.72/27 via 213.171.69.254 |
La única particularidad
es que nos inyeresa dar acceso directo a la red 212.95.203.72/27 . Si
no loiciéramos saldría a internet y se daría un
buen paseo para acceder a esa red. |
Preguntas:
- ¿Porqué no hemo usado las ips 192.168.0.152 y 192.168.0.153 en la configuración?
- La última orden de enrutado, es obvio su interés, pero qué pasará realmente si X accede por ejemplo a 212.95.203.77?
Otro ejemplo.
Es una modificación del ejemplo anterior donde se han eliminado los proveedores de ancho de banda reducido dejando dos proveedores P1 y P2. Para entenderlo debe estar claro lo que hemos hecho en el ejemplo anterior. La máquina D del ejemplo anterior la llamamos ahora R porque deja de actuar como servidor. Los servidores reales son las máquinas A, B, C, D, E y F. Una posible configuración sería asignar las IPs reales a estos servidores y que R haga proxyarp, como en el ejemplo anterior. Pero el router R1 es un CISCO al que no le gusta nada el proxyarp y se producen latencias en todos los paquetes que circulan hacia los servidores a traves de R1. Suele pasar que cuanto más caro es el router peor funciona. Hay otras configuraciones posibles:- Cambiar el cableado, eliminar R conectando los equipos a la misma red, la denominada en la figura "Red ext". No nos gusta queremos que R realice diversos funciones interesantes.
- Cambiar la máscara de red de los routers R1 y R2 para que solo vean a R y declarar que éste les enrutará hasta las otras IPs. Un problema para el proveedor P2, perdemos otra IP, solo tenemos 4.
- Usar DNAT y que R sea un firewall verdadero, pudiendo incluso hacer una distribución de carga estática sencilla.
Esta tabla es lo que causa que la página sea demasiado ancha
| F |
correo |
||||||||||||||||||||
| 192.168.0.85 |
certificado |
||||||||||||||||||||
|
|
A |
|
B |
|
C |
|
D |
|
E |
||||||||||||
| 192.168.0.96 | serv-pop |
192.168.0.100 | serv-DNS |
192.168.0.97 | serv-smtp
|
192.168.0.99 | serv-smtp |
192.168.0.101 | serv-www |
||||||||||||
| Red
int |
|||||||||||||||||||||
| SNAT |
192.168.0.98 |
DNAT |
|||||||||||||||||||
| R | 213.201.69.198 | 213.171.69.254 | |||||||||||||||||||
| Red
ajena |
|||||||||||||||||||||
| Red ext |
|||||||||||||||||||||
| 213.201.69.193 |
bridge |
192.168.1.x |
|||||||||||||||||||
| R1 |
nat por X | ||||||||||||||||||||
| wireless | ... |
... |
|||||||||||||||||||
| Proveedor | |||||||||||||||||||||
| bridge | 192.168.32.x | ||||||||||||||||||||
| nat
por X |
|||||||||||||||||||||
| 213.171.69.250 | |||||||||||||||||||||
| 213.171.69.249 |
X
externo |
||||||||||||||||||||
| R2 |
213.201.69.194 | ||||||||||||||||||||
| Proveedor | |||||||||||||||||||||
Configuración de A (idéntica a B,C,D,E):
ip a a 192.168.0.96/24 dev eth0 |
Esto es extremadamente fácil |
ip rou add default via 192.168.0.98 |
Configuración de R:
ip a a 192.168.0.98/24 dev eth0 |
Es su interfaz local. |
ip a a 213.201.69.198/27 dev eth1 |
Es el interfaz externo con dos
IPs . |
ip rou add default via 213.171.69.249 |
El tráfico por defecto lo
desvio por el proveedor P2 . Y ademas hace de SNAT para que toda la red "int" pueda salir a internet. |
ip r d default via 213.171.69.249 table R2 |
Dos trablas de rutas cada una
solo con una ruta por defecto al proveedor correspondiente. |
ip rule add from 213.201.69.198 table R1 |
Dos reglas para asociar cada IP
con su tabla. |
ip rule add to 192.168.0.0/24 lookup main |
No es estrictamente necesario
esta ver ... |
iptables -t nat -I PREROUTING -d 213.171.69.254 -p tcp |
Este DNAT provoca un balanceo de
carga al 50% hacia los equipos C y D. El pop3 va a A. El DNS a B. El DNS suele consultarse mediante UPD, no lo olvidemos ... El Web a E |
Este conjunto de reglas de DNAT podrían simpificarse así:
iptables -t nat -I PREROUTING -i eth1 -p tcp \ |
En lugar de especificar una
regla por cada una de las IP, indicamos que la condición se
extiende a cualquier IP del eth1 |
No obstante, esto puede no ser adecuado si por ejemplo queremos contabilizar por IP los paquetes que sufren DNAT, que podemos obtener usando iptables -t nat -L -n -x -v . Tampoco servirá si el ordenador destino cambia en función de la IP, de hecho es nuestro caso, considerando la presencia del servidor F. Hemos introducido una máquina F que es un servidor smtp que no tiene nada que ver con los servidores C y D, a los que actualmente se redirige el tráfico al puerto smtp. Por ello necesita su propia IP externa. Esto causa modificaciones a R, concretamente añadimos:
ip a a 213.201.69.199/27 dev eth1 |
Otra IP externa |
iptables -t nat -I PREROUTING -d 213.201.69.199 \ |
DNAT hacia F |
La configuración de F es la misma que A o B, etc.
Configuración de X:
ip a a 213.201.69.194/27 dev eth0 |
Obvio |
ip rou add default via 213.171.69.249 table R2 |
Dos tablas de rutas Y sus reglas |
iptables -t nat -A POSTROUTING -s 192.168.0.0/16 \ |
SNAT para la "Red ajena" |
Obsérvese que, como en el ejemplo anterior, el tráfico en las líneas va a depender de lo que digan los DNS, no fporma parte de la configuración.
Las máquinas de la "Red ajena" usan a X para que haga SNAT". Su configuración es extremadamente simple.
Preguntas:
- ¿Cuál es el error de concepción de la "Red ajena"?
- Si queremos montar en E una colección de servidores web
https, ¿cómo podemos hacerlo? (cada servidor ssl, virtual
o real, requiere una IP).
Un túnel IP-gre-IP ^
Este tipo de túnel va soportado directamente por el kernel de Linux. En la siguiente figura, ignoremos inicialmente las IPs en itálica.| A |
|
|
||||||||||
| 150.128.81.251 |
|
|||||||||||
| 192.168.254.254/32 | |
|||||||||||
| |
150.128.80.1 |
|
internet | |
213.171.69.249 |
|
||||||
| B |
||||||||||||
| 150.128.82.211 |
|
213.171.69.250 |
||||||||||
| red 150.128.80/21 |
red 213.171.69.248/29 |
150.128.81.194 |
Se trata de dos redes completamente distintas simplemente conectadas a través de Internet. Configurando A y B, deseo dar a B una IP de la red donde está A, concretamente la 150.128.81.194., y por supuesto, conectividad. Para ello establezco un túnel entre A y B del siguiente modo:
Configuración de A:
modprobe ip_gre |
Creo un túnel gre entre A y B y llamo al dispositivo virtual tunelito. |
ip addr add 192.168.254.254 dev tunelito |
Le doy una IP y lo activo. La IP es una cualquiera, elijo esa IP privada. |
ip route add 150.128.81.194 via 192.168.254.254 |
Podría poner: ip route add 150.128.81.194 dev tunelito |
ip neigh add proxy 150.128.81.194 dev eth0 |
Proxyarp para la IP asignada a B |
Configuración de B:
modprobe ip_gre |
Creo un túnel
gre entre A y B y llamo al dispositivo virtual tunelito. |
ip addr add 150.128.81.194/16 dev tunelito |
Le doy una IP y lo activo. Enruto toda la red 150.128.0.0/16 por el tunelito. ¡Ojo! He perdido la ruta real con 150.128.81.251 |
ip route add 192.168.254.254 via 150.128.81.194 |
Doy una ruta a la IP auxiliar
que hay en A |
ip route add 150.128.81.251/32 via 213.171.69.249 |
Este paso es necesario porque no puedo perder la ruta real a 150.128.81.251 |
Obsérvese que si accedo desde B a cualquier ordenador de la red de A, lo haré a través del túnel. Por ello los ordenadores verán un acceso desde 150.128.81.194 y no desde 213.171.69.250, que es lo que pretendo. Esto no es cierto para A, al que debo acceder sin túnel por necesidad (es quien soporta el túnel). Si quiero acceder de B a A a través del túnel lo haré con accediendo a la IP 192.168.254.254 y por ello B aparecerá ante A como 150.128.81.194.
Un ejercicio práctico ^
Un ordenador mío esté en una red privada de una empresa con conexión a Internet a través de un router con NAT. El router está configurado para realizar DNAT, de modo que si desde fuera de la empresa hago un ssh a la IP pública, el router redirige la conexión a éste ordenador. La IP actual del ordenador es 192.168.1.3 que pertenece al rango 192.168.1.X que es la red de la empresa, siendo la IP del router la 192.168.1.1.Me notifica la empresa que por la tarde van a cambiar las IPs privadas de 192.168.1.X a 192.168.10.X por diversas razones, y quiero cambiar la IP de mi ordandor a la 192.168.10.3, teniendo en cuenta que la IP del router será 192.168.10.1. ¿Cómo lo hago?
Una primera solución es fácil: conecto por ssh, cambio la configuración del equipo y les digo a los de la empresa que reinicien el equipo cuando hayan cambiado las IPS. El ordenador estará sin red un tiempo indeterminado.
Otra solución sin requerir reinicio es: conecto por ssh, cambio la configuración del equipo sin hacer efectivos los cambios y dejo éste proceso en ejecución:
while ping -c 1 192.168.1.1 >/dev/null 2>&1; do sleep 1; done ; /etc/init.d/network restartEs decir que cuando pierda el ping al router, reinicia sólo la red y coge la configuración nueva. El ordenador estará sin red unos segundos. Es una buena solución, salvo que haya un reinicio accidental antes del cambio de IP.
Una solución más complicada, es poner las 2 IPs al ordenador de modo que el cambio de IP ni se note apenas. Si hay un reinicio accidental no se notará si le pongo las 2 IPs por configuración. Para añadir la otra IP:
ip a a 192.168.10.3/24 dev eth0Es más complejo de lo que parece, pues sólo funciona una ruta por defecto. Para poner dos rutas por defecto, debo crear dos tablas de rutado, por ejemplo la 10 y la 20 y proceder como sigue:
ip r add 192.168.1.1 dev eth0 tab 10Ahora debo establecer cuando usar una tabla y cuando la otra:
ip r add default via 192.168.1.1 tab 10
ip r add 192.168.10.1 dev eth0 tab 20
ip r add default via 192.168.10.1 tab 20
ip rul add from 192.168.1.3 tab 10Esto establece que cuando los paquetes salgan con dirección 192.168.1.3 usarán la tabla 10 y cuando la dirección seleccionada sea la 192.168.10.3 usarán la tabla 20. Para ello debo asegurarme que las redes son disjuntas, por ejemplo, que usan máscara 24, es decir que he configurado la red con:
ip rul add from 192.168.10.3 tab 20
ip a a 192.168.1.3/24 dev eth0ip a a 192.168.10.3/24 dev eth0Si por error la red actual fuera de máscara 16, es decir que hubiera sido configurada con
ip a a 192.168.1.3/16 dev eth0habría problemas con las peticiones generadas desde el ordenador a la red 192.168.10.0/24, pues la IP 192.168.10.3 no se no se seleccionaría nunca como IP de origen. Tendría entonces que cambiar la máscara de red. La forma más segura de hacerlo es cambiando la configuración y reiniciando la red, pero en "plan suicida" podría ejecutar:
ip a d 192.168.1.3/16 dev eth0; ip a d 192.168.1.3/24 dev eth0; ip r add default via 192.168.1.1Si me equivoco al ejecutar el comando me quedo sin acceso al equipo. Es necesario ejecutar los comandos separados por ";", si no, tras el primer comando me quedo sin red.
Ejemplos MIME ^
Un mensaje que contiene una página web con una imagen incrustada:MIME-Version: 1.0 Content-Type: multipart/related; boundary=1904820100203140510CET --1904820100203140510CET Content-ID: <1904820100203140510CET.1> Content-Type: text/html Content-Transfer-Encoding: quoted-printable Content-Disposition: inline Esto es una imagen: <img = src=3D"cid:1904820100203140510CET.ca.gif"> --1904820100203140510CET Content-ID: <1904820100203140510CET.ca.gif> Content-Type: image/gif; name="ca.gif" Content-Transfer-Encoding: base64 Content-Disposition: inline R0lGODdhDQAJAIACAP8AAP//ACwAAAAADQAJAAACEIyPB8vNCY2bK0I6bcJOowIAOw== --1904820100203140510CET--
Un mensaje cifrado tiene este aspecto:
Subject: Pruebas-(S)MIME MIME-Version: 1.0 Content-Type: application/x-pkcs7-mime; name="smime.p7m" Content-Transfer-Encoding: base64 Content-Disposition: attachment; filename="smime.p7m" Content-Description: S/MIME Encrypted Message MIAGCSqGSIb3DQEHA6CAMIIBggIBADGB9jCB8wIBADCBrDCBpTELMAkGA1UEBhMC RVMxETAPBgNVBAgUCENhc3RlbGzzMREwDwYDVQQHFAhDYXN0ZWxs8zEWMBQGA1UE ChMNTmlzdSBTZWN1cml0eTEXMBUGA1UECxMOQ2VydCBBdXRob3JpdHkxITAfBgNV BAMTGE5pc3UgU2VjdXJpdHkgQ0EgQ2xhc3MgMTEcMBoGCSqGSIb3DQEJARYNaW5m b0BuaXN1Lm9yZwICAWUwDQYJKoZIhvcNAQEBBQAEMBdOfJ7M0+80awpCStqW+W2o 0ikvCjcXr7h71S1BeiUBCEgXp6Ygb+F2YciHBzhzjjCBgwYJKoZIhvcNAQcGMBQG CCqGSIb3DQMHBAhn8lpGTbJ7EIBgjHcc55BUOpGh+FXKFiaOPkBkt7Cs8eWtn88Q g+dSLCBBewhs6oAKLoLQQeRwl+AzVjFj97tEcrGRvDL4kwYlo86X59hlMQnxynUL Y/Dg5PlAep4AKZSMR+U0UYrJPfzMAAAAAA==Como puede verse el cuerpo es un bloque cifrado que no puede leerse si no se es el propietario de la llave que lo descifra. Puede leerse empleando la llave y el certificado que están aquí.
El siguiente mensaje está firmado. Contiene dos partes, la primera es el mensaje sin firmar, que se compone a su vez de dos partes MIME y la segunda es la firma:
Subject: Pruebas-(S)MIME MIME-Version: 1.0 Content-Type: multipart/signed; protocol="application/x-pkcs7-signature"; micalg=sha1; boundary="15284126535786313362" This is a cryptographically signed message in MIME format. --15284126535786313362 Content-Type: multipart/mixed; boundary=1528412653578631336-1 If you are reading this part you should use a MIME reader. --15284126535786313362-1 Content-Type: text/plain Content-Transfer-Encoding: quoted-printable Este mail firmado lleva una peque=F1a imagen --15284126535786313362-1 Content-Type: image/gif; name="sound2.gif" Content-Transfer-Encoding: base64 Content-Disposition: inline R0lGODlhFAAWAMIAAP///8z//8zMzJmZmWZmZjMzMwAAAAAAACH+TlRoaXMgYXJ0IGlzIGlu IHRoZSBwdWJsaWMgZG9tYWluLiBLZXZpbiBIdWdoZXMsIGtldmluaEBlaXQuY29tLCBTZXB0 ZW1iZXIgMTk5NQAh+QQBAAABACwAAAAAFAAWAAADUBi63P7OSPikLXRZQySmGyF6UCgKV8md m/FFHHqRVVvcNOzdSt7sr4CPMRS6VC8bsmcADIrMT/M5VBo3QYkzh81ufTce0Zph7sqMcBDN XiQAADs= --15284126535786313362-1-- --15284126535786313362 Content-Type: application/x-pkcs7-signature; name="smime.p7s" Content-Transfer-Encoding: base64 Content-Disposition: attachment; filename="smime.p7s" Content-Description: S/MIME Cryptographic Signature MIAGCSqGSIb3DQEHAqCAMIIGzAIBATEJMAcGBSsOAwIaMIAGCSqGSIb3DQEHAQAA oIIFRjCCBUIwggQqoAMCAQICAgFlMA0GCSqGSIb3DQEBBAUAMIGlMQswCQYDVQQG EwJFUzERMA8GA1UECBQIQ2FzdGVsbPMxETAPBgNVBAcUCENhc3RlbGzzMRYwFAYD VQQKEw1OaXN1IFNlY3VyaXR5MRcwFQYDVQQLEw5DZXJ0IEF1dGhvcml0eTEhMB8G A1UEAxMYTmlzdSBTZWN1cml0eSBDQSBDbGFzcyAxMRwwGgYJKoZIhvcNAQkBFg1p bmZvQG5pc3Uub3JnMB4XDTk5MTIzMTEyMTI1NloXDTAwMTIzMDEyMTI1NlowgZMx CzAJBgNVBAYTAlhYMQ0wCwYDVQQIEwROb25lMQ0wCwYDVQQHEwROb25lMQ0wCwYD VQQKEwROb25lMQ0wCwYDVQQLEwROb25lMScwJQYDVQQDEx5UaGlzIGlzIGFuIGlu dmFsaWQgY2VydGlmaWNhdGUxHzAdBgkqhkiG9w0BCQEWEG5vbmVAbm9uZS5hdC5h bGwwTDANBgkqhkiG9w0BAQEFAAM7ADA4AjEAxJMJP2aUJ2ak95OgajEemVBw9Ucs YXS2L4guFbrzNKbCe0o3NupNvW4e5dtYC8NBAgMBAAGjggJiMIICXjAJBgNVHRME AjAAMCsGCWCGSAGG+EIBBAQeFhxodHRwOi8vY2EubmlzdS5vcmcvbmlzdTEuY3Js MIICIgYJYIZIAYb4QgENBIICExaCAg9UaGlzIENlcnRpZmljYXRlIGVuc3VyZXMg b25seSB0aGF0IHRoZSBzdWJqZWN0IHRoYXQgaGF2ZSByZXF1ZXN0ZWQgaXQgaXMg Y2FwYWJsZSBvZiByZWFkaW5nIHRoZSBtYWlsIHNlbnQgdG8gdGhlIGFkZHJlc3Mg aW5jbHVkZWQgb24gdGhlIERpc3Rpbmd1aXNoZWQgTmFtZS4gU28sIHRoaXMgQ2Vy dGlmaWNhdGUgZG9lcyBub3QgZXN0YWJsaXNoIGFueSByZWxhdGlvbiBiZXR3ZWVu IHRoZSBtYWlsIGFkZHJlc3MgYW5kIHRoZSByZXN0IG9mIHRoZSBkYXRhIGluY2x1 ZGVkIG9uIHRoZSBEaXN0aW5ndWlzaGVkIE5hbWUsIHRoYXQgaGF2ZSBiZWVuIGlu Y2x1ZGVkIGluIHRoZSBDZXJ0aWZpY2F0ZSB3aXRob3V0IHByZXZpb3VzIHZhbGlk YXRpb24uIE5pc3UgU2VjdXJpdHkgZG9lcyBub3QgZ2l2ZSBhbnkgZ3VhcmFudGVl IGZvciB0aGlzIGNlcnRpZmljYXRlLCBhbmQgZG9lcyBub3QgaGF2ZSBhbnkgcmVz cG9uc2liaWxpdHkgaW4gYW55IGNpcmN1bXN0YW5jZS4gUmVhZCBodHRwOi8vY2Eu bmlzdS5vcmcvZGlzY2xhaW0uaHRtbDANBgkqhkiG9w0BAQQFAAOCAQEAwCZ8GBcq F7YcysBBc30JObb82i+Br6ucmQLvnu2FCowk1Mv/94V5tRR5gUnSojtnR4Gqp8I6 U2NyFNxHgYczj6GEH33Vzm13nkg9k8SvsKUN6Pq7jpVHLdtoZkqpyFjcTkHS2FbW mXik3FjY+w8YGztf78SgZ8zIged0BBfVcKRjBDFnpKenQrWgntlZeqbO+i7lY6Wi AMCgj45L7inFa0JXV+V7+8q7nj4NT1Try/VmEH3nIgkN7D3CVg0uHMrZf/QbWTa0 mA/9Y6BFwDs7WLsD1PK/9TW7SrB3J8dq3pXFAV7onl410Wk2Z2U6N/0vS3MjlgHZ qSDtgu0HgCWAOjGCAWEwggFdAgEBMIGsMIGlMQswCQYDVQQGEwJFUzERMA8GA1UE CBQIQ2FzdGVsbPMxETAPBgNVBAcUCENhc3RlbGzzMRYwFAYDVQQKEw1OaXN1IFNl Y3VyaXR5MRcwFQYDVQQLEw5DZXJ0IEF1dGhvcml0eTEhMB8GA1UEAxMYTmlzdSBT ZWN1cml0eSBDQSBDbGFzcyAxMRwwGgYJKoZIhvcNAQkBFg1pbmZvQG5pc3Uub3Jn AgIBZTAJBgUrDgMCGgUAoF0wGAYJKoZIhvcNAQkDMQsGCSqGSIb3DQEHATAcBgkq hkiG9w0BCQUxDxcNMDAwMjExMTA1NjQ5WjAjBgkqhkiG9w0BCQQxFgQUpjukrrfw 2rb9f9BrmNDjCedNiKkwDQYJKoZIhvcNAQEBBQAEMCz6nT9sXV4V3DvjtuBpVnuY CSd3KUQJu/tIzueYdcwDKEQyWlrXltCE112jBTHQHAAAAAA= --15284126535786313362--